
When our research team first took on the challenge of developing YOLO-Pro, the goal was clear: to build a modern family of object detection architectures that deliver state-of-the-art performance on edge devices, under real constraints, with real-world latency, memory, and power limits, backed by permissive licensing.
Since our initial announcement post, YOLO‑Pro has evolved from a preview to a production-proven model family. Along the way, it’s been iterated on, stress-tested, benchmarked, and deployed across a wide range of datasets, model sizes, and hardware targets. And today, we’re excited to announce that YOLO‑Pro is officially generally available. 🙌
But moving from developer preview to general availability doesn’t come from optimism; it comes from evidence.
In this post, we’ll walk through the benchmark results that gave the team confidence to make that call. We’ll break down how YOLO‑Pro compares against widely used YOLO families like YOLOv11 and YOLOv5, evaluate both float32 and int8 performance, and examine how these models behave across multiple sizes and datasets.
Let’s dig into the data.
A quick recap
Traditional YOLO models are powerful, but they were designed with cloud environments and academic datasets like COCO in mind, with restrictive licensing for commercial use.
YOLO-Pro flips that paradigm. Edge Impulse engineered these models from the ground up to excel in real-word edge deployments. That means better performance, lower latency, and smarter resource usage for your embedded object detection projects, all available as a part of the Edge Impulse platform and governed by our terms of use.
Models compared
To compare performance, we assessed YOLO-Pro, YOLOv11, and YOLOv5 models at four different sizes: nano, small, medium, and large. We used YOLOv11 and YOLOv5 as they are the two most frequently used YOLO models within the Edge Impulse developer community.
Model size parameter counts:
| nano | small | medium | large | |
|---|---|---|---|---|
| YOLO-Pro | 2.3 M | 7.2 M | 17.8 M | 32.6 M |
| YOLOv11 | 2.6 M | 9.4 M | 20.0 M | 25.2 M |
| YOLOv5 | 1.8 M | 7.0 M | 20.8 M | 46.1 M |
Results summary
We compared YOLO-Pro performance against YOLOv11 and YOLOv5 in two ways: using eight specifically selected datasets and ninety-five sampled real-world projects. See the respective sections of this post for the methodologies and detailed results.
The benchmarking showed that YOLO‑Pro is a strong alternative to YOLOv11 and YOLOv5, typically delivering better performance than both model families at int8 precision, while achieving performance comparable to YOLOv11, and often exceeding YOLOv5, at float32 precision.
Across a wide range of real‑world conditions, YOLO‑Pro demonstrates robust int8 performance, which is critical for fast, efficient inference on embedded hardware. It excels in fixed‑camera deployments with small and dense bounding boxes, variable backgrounds, mixed color and grayscale inputs, partial occlusion, and changing perspectives, supporting both industrial vision and augmented reality use cases.
We’re happy to have a strong baseline to build upon. The story does not end here though. Check out the What’s next for YOLO-Pro section at the end of this post to see what’s coming.
Notable results across the eight datasets selected for benchmarking:
- YOLO-Pro far out performs YOLOv11 at int8 precision, largely due to an insurmountable amount of error introduced through post training quantization of the YOLOv11 models (a known issue with YOLO models since YOLOv8, and something that we addressed in the development of YOLO-Pro)
- YOLO-Pro had better results compared to YOLOv5 at all four model sizes tested with int8 precision
On a sample of ninety-five real-world projects, YOLO-Pro consistently outperforms YOLOv11 and YOLOv5 at int8 precision:
| int8 | float32 | |||
|---|---|---|---|---|
| Model | YOLO-Pro | YOLOv11 | YOLO-Pro | YOLOv11 |
| Top performing project count | 70 | 25 | 37 | 58 |
| Top performing project percentage | 74% | 26% | 39% | 61% |
| int8 | float32 | |||
|---|---|---|---|---|
| Model | YOLO-Pro | YOLOv11 | YOLO-Pro | YOLOv11 |
| Top performing project count | 89 | 6 | 78 | 7 |
| Top performing project percentage | 94% | 6% | 82% | 18% |
Benchmark one: selected datasets
We assessed the performance of YOLO-Pro across eight permissibly licensed datasets that captured a variety of scenarios and potential applications. These datasets were chosen for their representative aspects that one may come across in industrial tasks: fixed camera positions, variable backgrounds, different object orientations and sizes, partial occlusion, and other factors.
Methodology
YOLO-Pro, YOLOv11, and YOLOv5 models were trained once against each of the selected dataset. The caveat to training once is that, in the case when YOLOv11 exhibited catastrophic failure for int8 model precision, it was retrained to ensure the failures were indeed consistent behavior.
The training run for each model consisted of 100 epochs and had input image resolution matched for each comparison (320x320x3 or 640x640x3). The performance of each model, assessed by mAP@[.5:.95] (mean average precision over IoU thresholds from 0.5 to 0.95) scores on the test samples, was calculated using float32 and int8 precision TensorFlow Lite models within Edge Impulse.
Note that the default YOLO-Pro architecture option is No Attention with ReLU because it has the widest hardware compatibility. However, Attention with SiLU was selected for benchmarking to match the SiLU activation function in YOLOv11 and YOLOv5.
Analysis
An analysis for each dataset can be found in the sections to follow. Before diving into individual datasets, it’s worth clarifying how to read the results that follow. For each dataset, we report both float32 and int8 precision. The float32 numbers provide a useful reference for raw model capability, but the analysis gets more interesting when looking at int8 results, as these most closely reflect how the models are deployed in practice on edge devices.
Datasets:
- Bottle crate
- Cat vs dog
- Parking lot occupancy
- PCBs on a conveyor belt
- Trail camera
- Trash bin in urban settings
- Washers and bolts
- Worker assistant
Bottle crate dataset
Takeaway: YOLO-Pro is a great choice of int8 model for fixed camera position and consistently sized small bounding box applications.
| Description | Images of a bottle crate, seen from above, in various orientations with bottles that have their lids on and off |
| Objects | 2 (empty, full) |
| Training samples | 97 |
| Testing samples | 33 |
| Image resolution | 320x320x3 |

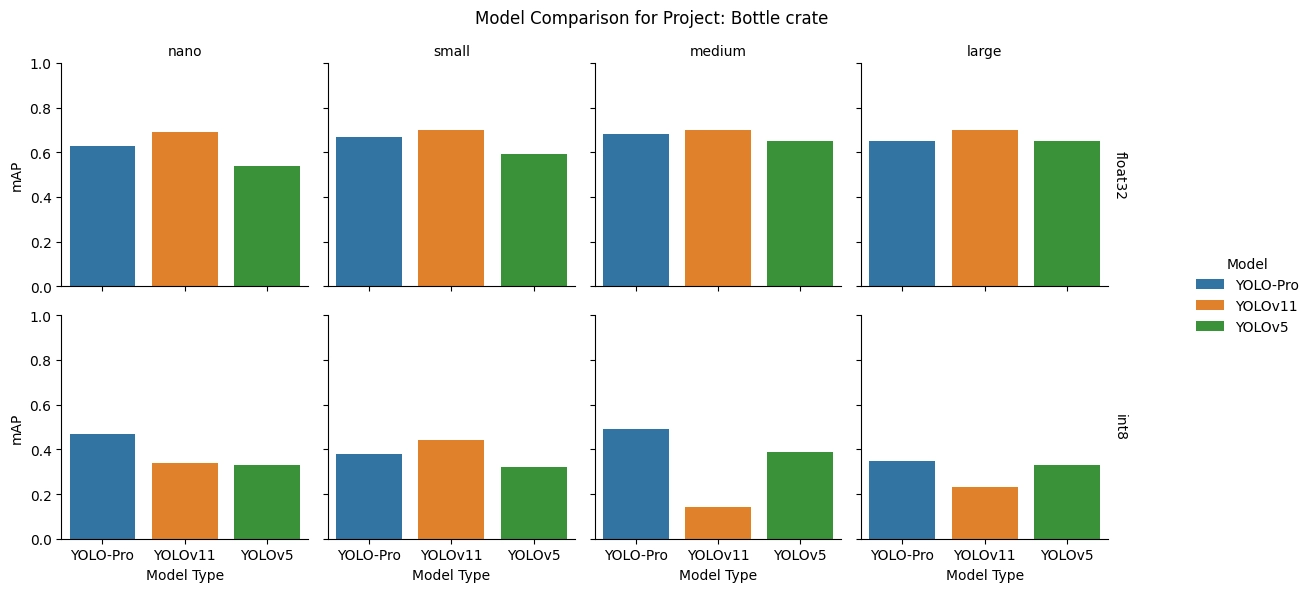
float32: YOLOv11 consistently led mAP across all model sizes, with YOLO‑Pro tracking closely behind and YOLOv5 trailing throughout.
int8: Quantization shifted the balance. YOLO‑Pro emerged as the strongest option at the nano, medium, and large sizes, while YOLOv11 retained a narrow lead only at the small size. YOLOv5 improved relative placement as model size increased.
Cat vs dog dataset
Takeaway: YOLO-Pro performs well on this commonly used dataset where there are highly divergent backgrounds and many different sized bounding boxes that appear all over the images.
| Description | Images of cats and dogs with their faces labelled in various indoor and outdoor settings |
| Objects | 2 (cat, dog) |
| Training samples | 2,323 |
| Testing samples | 590 |
| Image resolution | 320x320x3 |
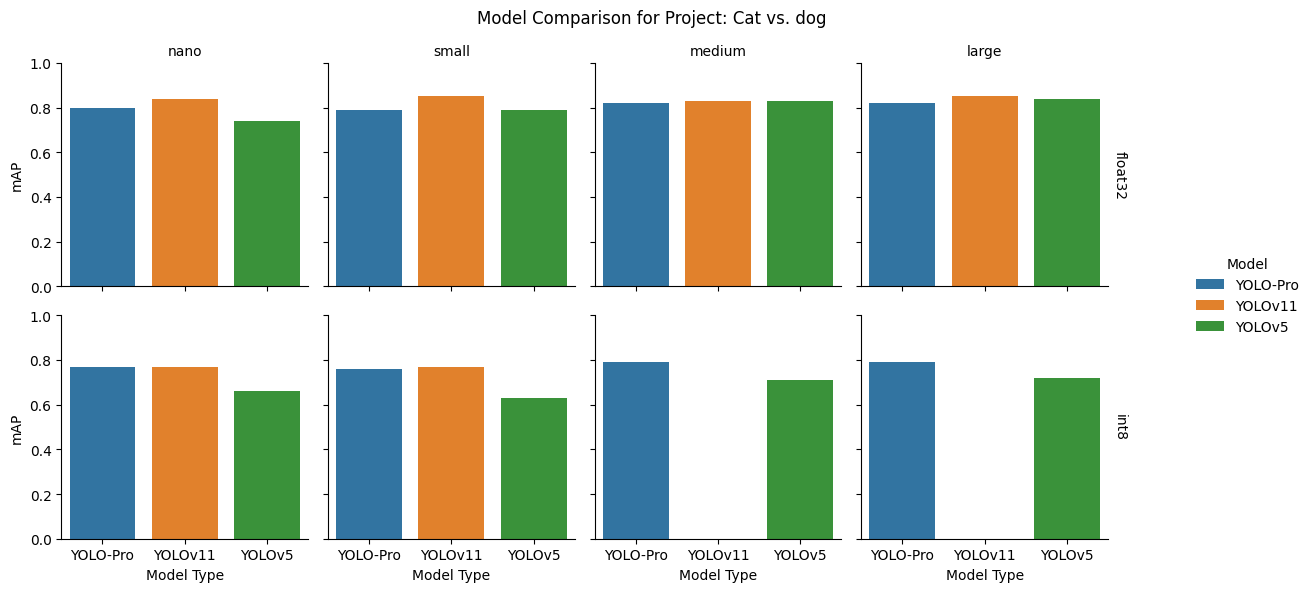
float32: YOLOv11 took the top spot across all model sizes, while second place alternated with YOLO‑Pro leading at the smaller sizes and YOLOv5 at the larger variants.
int8: Post‑quantization, YOLOv11 remained competitive at nano and small but suffered severe degradation at medium and large. YOLO‑Pro held a clear advantage over YOLOv5 across all sizes and remained close to YOLOv11 where the latter held up.
Parking lot occupancy dataset
Takeaway: YOLO-Pro can perform well with datasets that have a large number of bounding boxes in images. This result also shows another fixed camera example where YOLO-Pro performs well.
| Description | Images of cars in a parking lot taken from a fixed place camera above the lot |
| Objects | 1 (car) |
| Training samples | 3,594 |
| Testing samples | 879 |
| Image resolution | 320x320x3 |

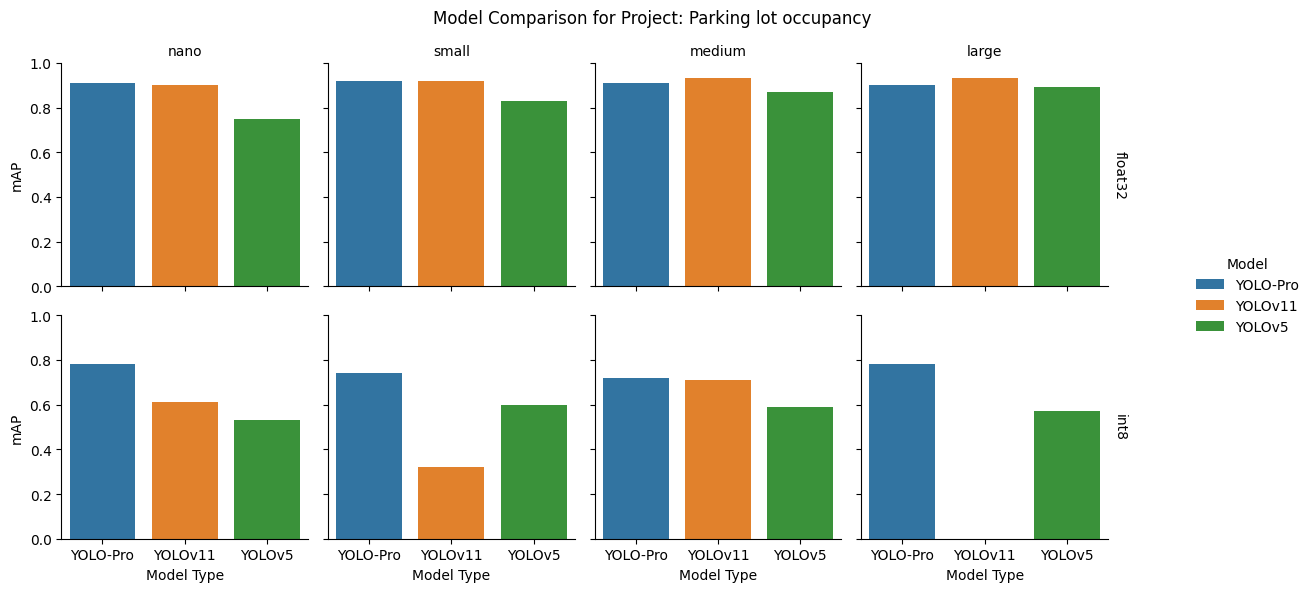
float32: YOLO‑Pro led at the nano and small sizes, while YOLOv11 overtook it at the medium and large scales. YOLOv5 consistently ranked third.
int8: After quantization, YOLO‑Pro delivered the most stable performance across all four sizes. YOLOv11 and YOLOv5 varied more widely, with YOLOv11 exhibiting a pronounced failure at the large size.
PCBs on a conveyor belt dataset
Takeaway: YOLO-Pro is a good choice for fixed camera conveyor belt style applications even when the bounding boxes are quite small and there are multiple different objects to be detected.
| Description | Images of development board PCB assemblies in various orientations and configurations on a conveyor belt |
| Objects | 3 (mmp2, z3, zp3) |
| Training samples | 1,117 |
| Testing samples | 140 |
| Image resolution | 640x640x3 |

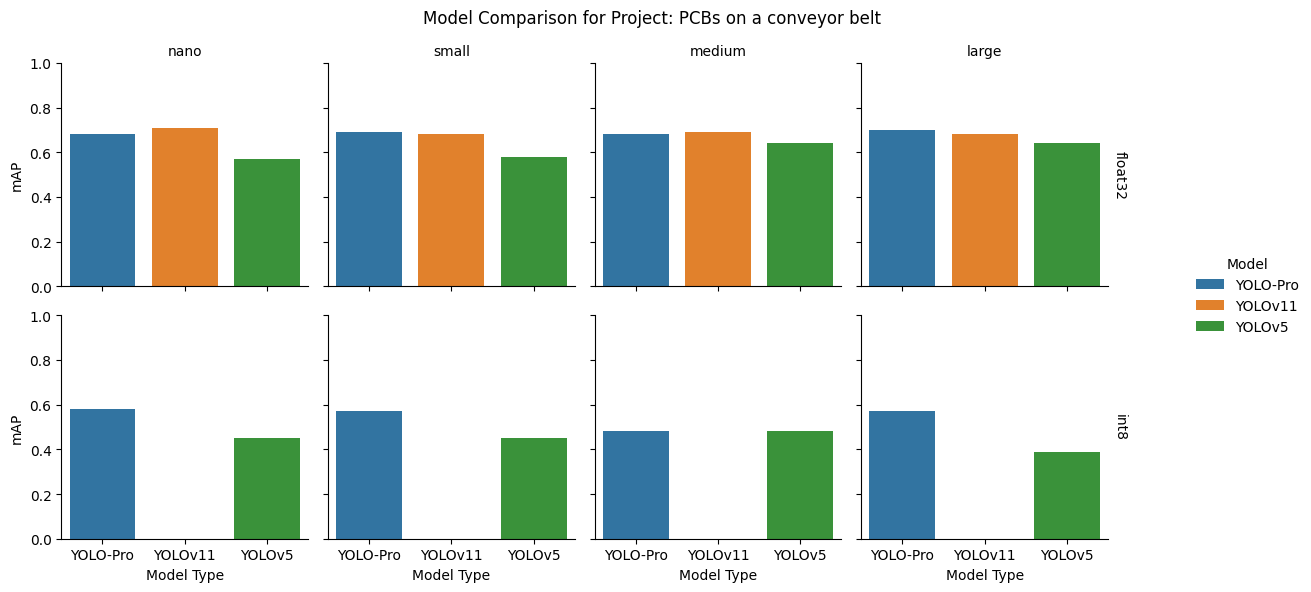
float32: Performance leadership split by size: YOLO‑Pro topped the small and large models, while YOLOv11 performed best at nano and medium. YOLOv5 again occupied third place throughout.
int8: Quantized results favoured YOLO‑Pro at every size. YOLOv11 showed catastrophic degradation for this dataset across the entire range of model sizes.
Trail camera dataset
Takeaway: YOLO-Pro performs well with datasets that include varying light conditions and a mixture of color and graycale images.
| Description | Images of animals from an outdoor trail camera at different times of the day and multiple locations |
| Objects | 2 (deer, hog) |
| Training samples | 1,180 |
| Testing samples | 131 |
| Image resolution | 320x320x3 (nano, small); 640x640x3 (medium, large) |

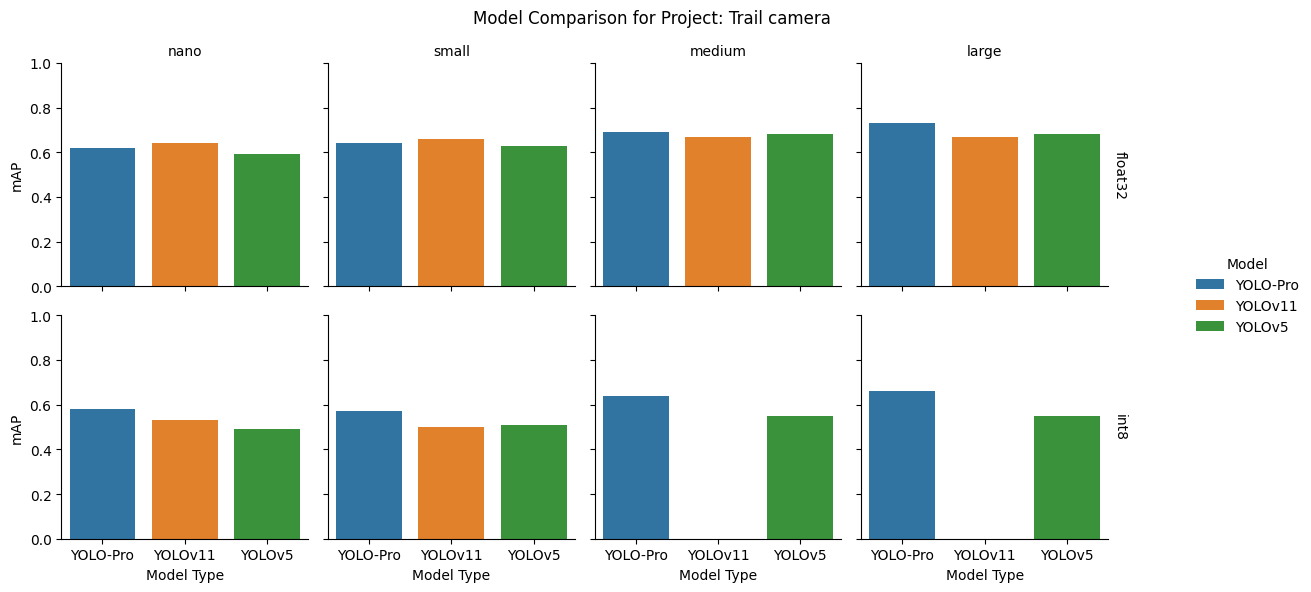
float32: YOLO‑Pro performed best at the medium and large sizes, while YOLOv11 led at nano and small. YOLOv5 was more competitive at larger sizes but lagged at the smaller ones.
int8: YOLO‑Pro maintained clear leadership after quantization. YOLOv11 failed at the medium and large sizes, and YOLOv5 and YOLOv11 swapped relative positions between nano and small.
Trash bin in urban settings dataset
Takeaway: YOLO-Pro can be used where objects are partially obscured, where the viewing angle of the object changes, and where the background is varied and diverse.
| Description | Images of trash bins, viewed from different angles, in various outdoor settings |
| Objects | 1 (container) |
| Training samples | 2,126 |
| Testing samples | 1,164 |
| Image resolution | 320x320x3 |

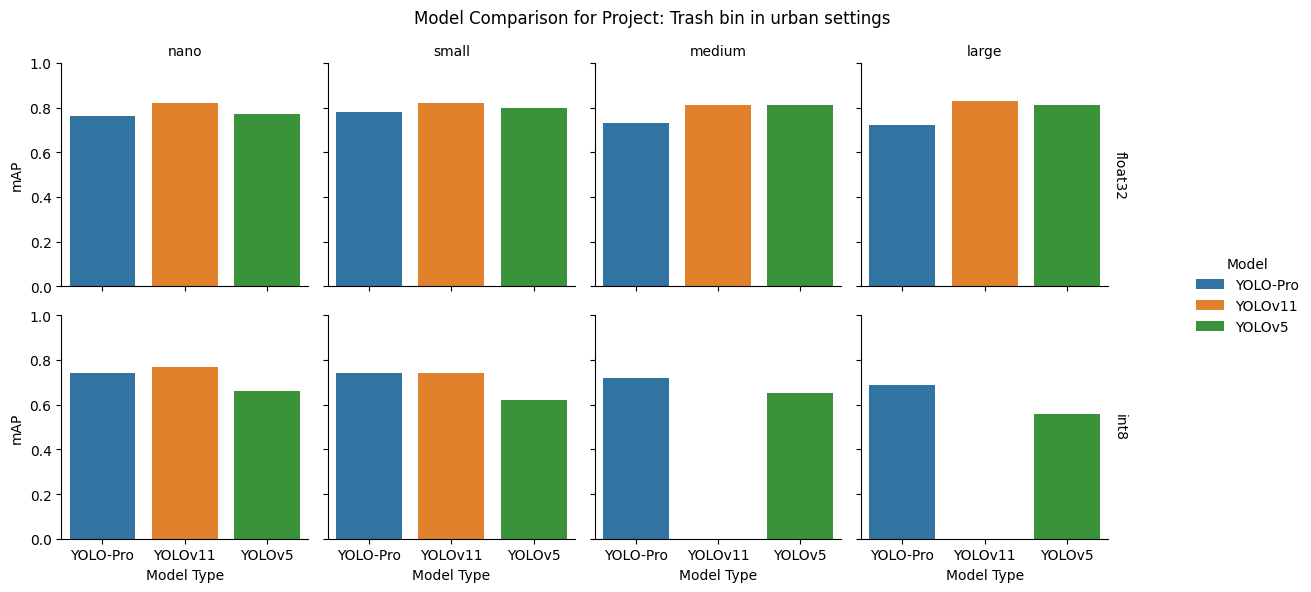
float32: YOLOv11 consistently achieved the highest mAP across all sizes, with YOLOv5 following closely and YOLO‑Pro remaining competitive, particularly at the smaller scales.
int8: Quantization exposed a sharp inflection: YOLOv11 remained strong at nano and small but broke down at medium and large. YOLO‑Pro surpassed YOLOv5 at all model sizes after quantization and led at the larger sizes.
Washers and bolts dataset
Takeaway: YOLO-Pro is robust to varying backgrounds and can also generalize to different perspectives and sizes of the same object.
| Description | Images of bolts, nuts, and washers on various worktops in different orientations and lighting conditions |
| Objects | 3 (bolt, nut, washer) |
| Training samples | 284 |
| Testing samples | 72 |
| Image resolution | 320x320x3 (nano, small); 640x640x3 (medium, large) |

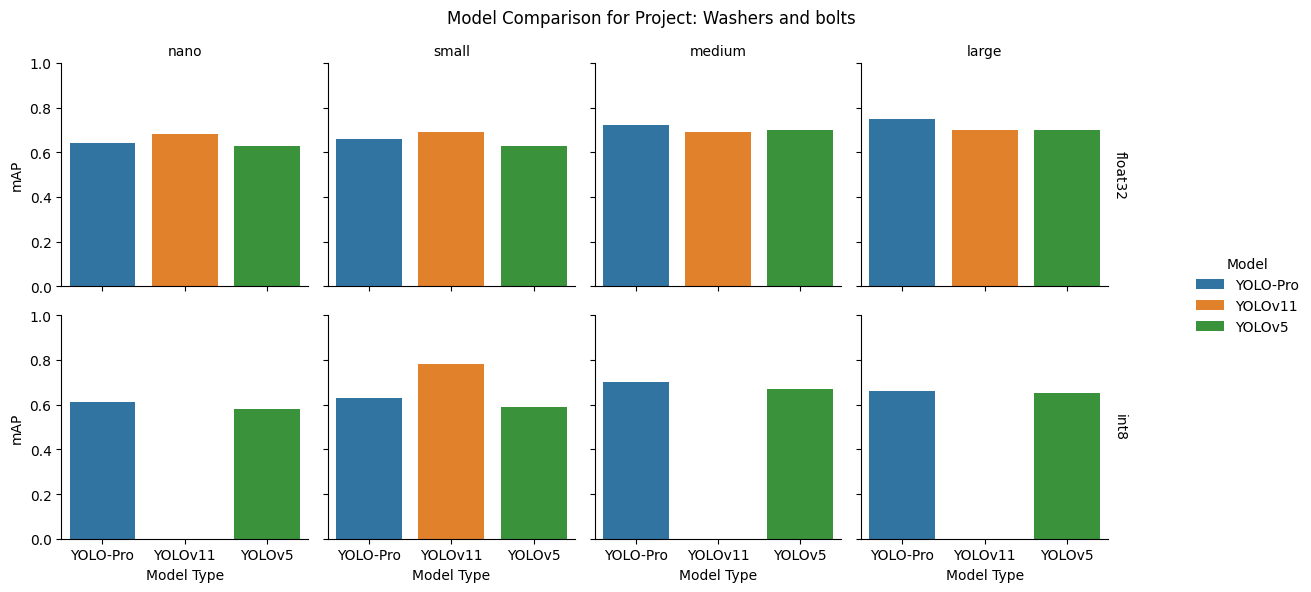
float32: YOLOv11 led at the nano and small sizes and remained competitive elsewhere, while YOLO-Pro led at the medium and large model sizes. YOLOv5 showed stronger results at medium and large than at the smaller sizes.
int8: YOLO‑Pro was the most reliable option overall, leading at nano, medium, and large model sizes. Only the small YOLOv11 model retained strong performance after quantization, while the others failed.
Worker assistant dataset
Takeaway: YOLO-Pro is suitable for using for augmented reality applications in industrial use cases.
| Description | Images taken from first person perspective of various industrial parts being held in the user's hand |
| Objects | 4 (controller, gauge, solenoid, valve) |
| Training samples | 794 |
| Testing samples | 228 |
| Image resolution | 640x640x3 |
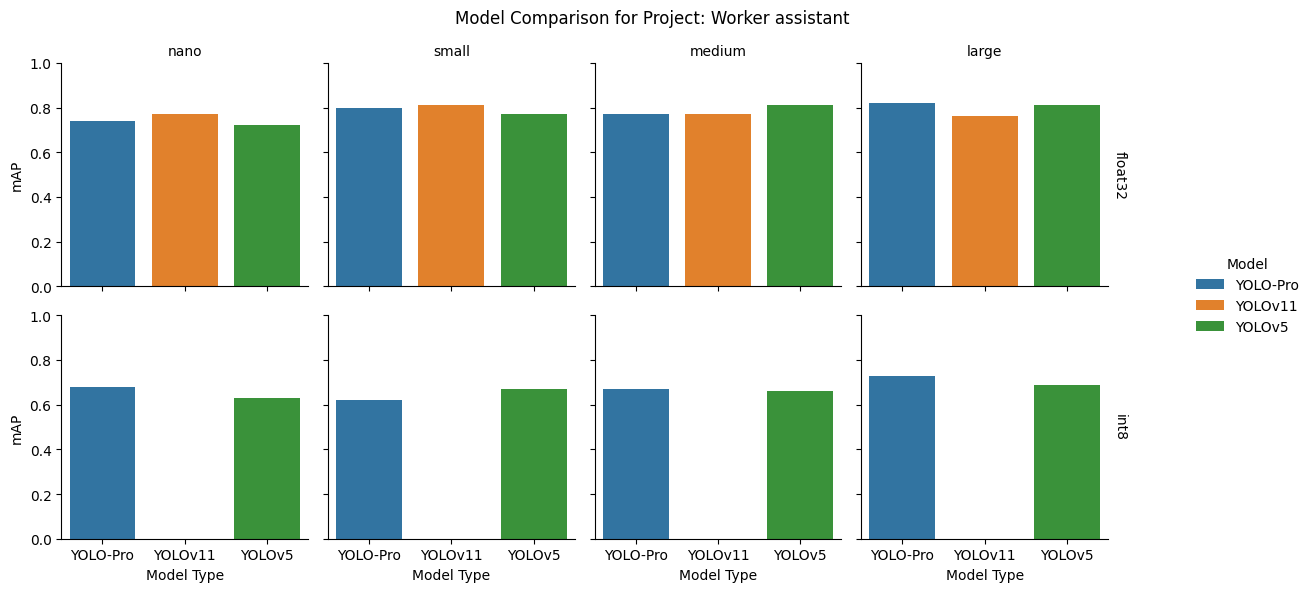
float32: While YOLOv11 led at the smaller scales, this dataset showed uncommon behavior: YOLOv5 topped the medium model. YOLO‑Pro led at the large size.
int8: After quantization, YOLO‑Pro commanded the top spot at nano, medium, and large model sizes, while YOLOv5 unexpectedly took the lead at small. YOLOv11 failed catastrophically across all sizes.
Benchmark two: real-world projects
To test the performance of YOLO-Pro on a wider range of data that provides real-world relevance, we selected a sampling of ninety-five projects using the older YOLOv5 architecture from the Edge Impulse community with the curiosity of seeing if YOLO-Pro could improve the performance.
Methodology
We generated a list of all existing Edge Impulse projects using YOLOv5. Poorly performing projects — those containing less than fifty training samples and those that had mAP scores lower than 0.1 — were filtered out. From the projects remaining, ninety-five projects were randomly sampled. YOLO-Pro, YOLOv11, and YOLOv5 models were then trained on the project dataset using the same image input resolution and model size used in the original project, and performance compared across the model families.
As with the previous benchmark, the training run for each model consisted of 100 epochs, using YOLO-Pro’s No Attention with SiLU architecture to match the SiLU activation function in YOLOv11 and YOLOv5. The performance of each model, assessed by mAP@[.5:.95] scores on the test samples, was calculated using float32 and int8 precision TensorFlow Lite models within Edge Impulse. The mean of the resulting mAP scores for YOLOv11 and YOLOv5 was then calculated and made relative to the YOLO-Pro results.
Further, since the parameter count for each model at a specific size is not the same across the model families, the mAP scores were normalized based on model parameter count for these project model comparisons to see the impact that the number of model parameters has on performance. For each result, the mAP result was divided by the parameter count of the model to give a mAP per parameter score, the mean mAP per parameter scores were calculated for each model family, and then the YOLOv11 and YOLOv5 results were again made relative to those from YOLO-Pro.
Analysis
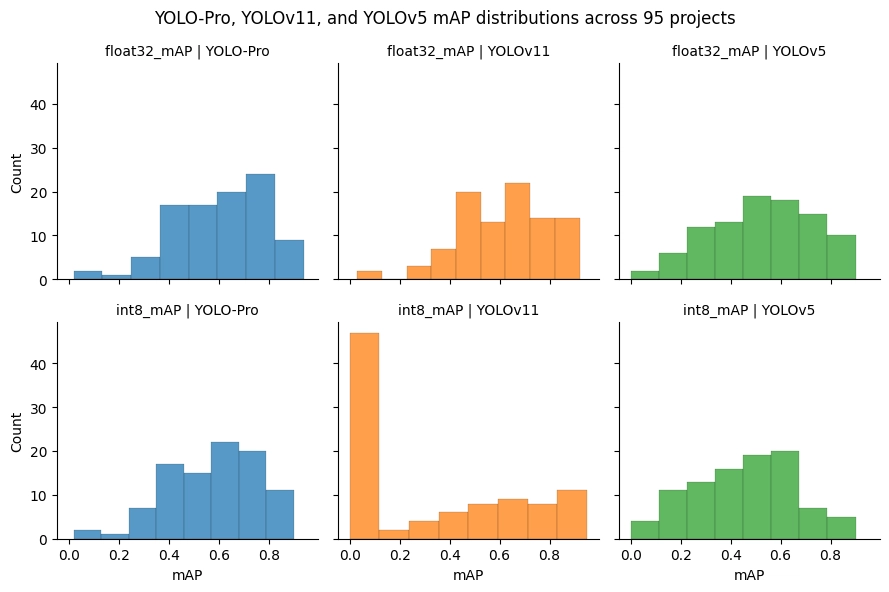
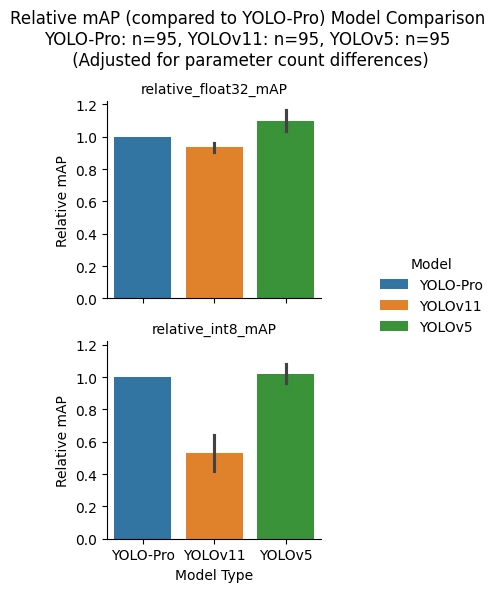
The figure above shows the mAP score distributions for each model family across the ninety-five sampled projects. The distributions are somewhat similar asides from the exception of the large bar on the left hand side of the YOLOv11 int8 distribution due to the quantization errors for this model architecture that have already been shown to occur. From this data, the mean mAP scores across all projects for each model family were computed and compared relative to the YOLO-Pro results.
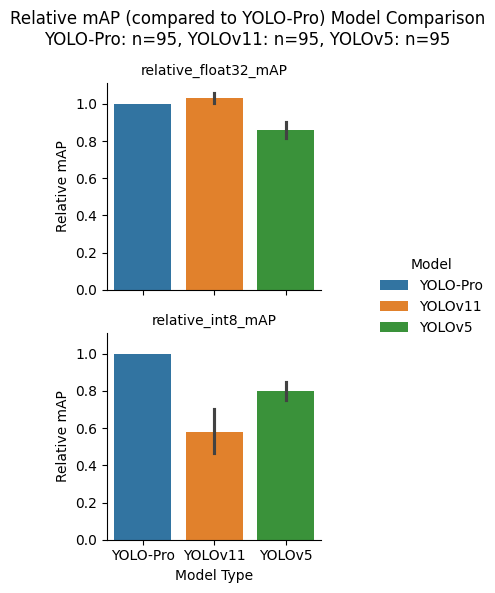
As can be seen in the figure above, YOLO-Pro has similar performance to YOLOv11 at float32 precision. At int8 precision, however, YOLO-Pro significantly outperforms both YOLOv11, due to the catastrophic quantization error that was demonstrated in the previous eight dataset results, and YOLOv5.
After taking into consideration model parameter count, the picture changes. YOLOv5 now has the highest mAP at float32 precisions and only slightly beats out YOLO-Pro at int8 precision. One thing to note, is that eighty out of the ninety-five sampled projects used the nano model size (a trend we have seen before; we are deploying to the edge after all), where YOLOv5 has the lowest number of parameters. If there had been more small, medium, and large models used within the sampled projects, the results may not have been skewed as much in favor of YOLOv5.
Understanding what makes YOLOv5 more efficient per parameter at the nano model size, and performing further analysis at the larger model sizes, will be an interesting future research direction.
General availability: what changes now
In practical terms, not much! That’s intentional.
YOLO‑Pro has already been available within the Edge Impulse platform and used across a wide range of projects during its developer preview phase. With general availability, the underlying models, tooling, and workflows remain the same.
What does change is primarily about confidence and commitment:
- YOLO‑Pro is now a trusted object detection architecture
- The developer preview label has been removed
- We stand behind its stability, performance, and forward compatibility
Just as importantly, general availability doesn’t mean “done.” We’ll continue to evolve YOLO‑Pro based on concrete usage, new datasets, and feedback from developers deploying at the edge. If you’re already using YOLO‑Pro, you don’t need to change anything. And if you’re new to it, now is a great time to start exploring the model family.
What’s next for YOLO-Pro
As mentioned earlier in this post, having baseline benchmark results is not the end for YOLO-Pro development. From here, the team has future plans to create model variants optimized for specific industrial object detection tasks, add support for additional model heads such as segmentation and pose detection, and more. Along the way, we will also be listening to, and incorporating, feedback from the community. Please do share your use cases, experiences, and suggestions on where YOLO-Pro can be improved; we’d love to hear how you’re using the model.