
A recent report by the Occupational Safety and Health Administration (OSHA) has revealed a disturbing trend of increasing accidents in the workplace. The report shows that the number of workplace accidents has risen by 5% in the past year, resulting in a significant increase in both human injuries and financial costs for companies.
The human cost of these accidents is staggering, with over 2,500 workers losing their lives each year as a result of workplace accidents. In addition, over four million workers are injured on the job annually, resulting in billions of dollars in medical expenses and lost productivity.
The financial cost to companies is also significant, with the average cost of a workplace accident estimated to be around $40,000. This includes costs such as medical expenses, workers’ compensation, and lost productivity. These costs can be devastating for small businesses, and can even lead to bankruptcy for some companies.
One of the key challenges in addressing workplace accidents is the lack of reporting. The OSHA report found that only 30% of companies reported their accidents, with many companies choosing to keep incidents hidden in order to avoid penalties and negative publicity.

To address this issue, OSHA has implemented new reporting requirements for companies in high-risk industries. Of course with any new process such as this, there is a good deal of overhead involved in implementing it. This is at least part of the reason why only 30% of companies report their accidents as required. So to make our workplaces safer, innovation is needed to make accident reporting simpler and quicker.
Nekhil Ravi is the type of person that always has a solution when presented with a problem, and workplace accident reporting is no exception. Drawing on his past experience with machine learning, he realized that the answer could be as easy as speaking the word “accident.” While it is true that before a new method can be rolled out for real-world use, it may need some additional features — like logging of events, or recording audio reports of the incident that has occurred, for example — his proof of concept shows how to get the reporting process started.
Ravi’s plan was to build a tiny, low-cost device that could be distributed widely around a workplace. This device would continually monitor sounds in the area and feed them into a machine learning model built with Edge Impulse Studio that can spot the keyword “accident.” It is beyond the scope of this proof of concept, but it is easy to imagine how this trigger could initiate the collection of a full report.
The Nordic Thingy:53 IoT prototyping platform was chosen as the hardware, because it checked all of the boxes for the project’s requirements — small, inexpensive, and powerful. With a 128 MHz Arm Cortex-M33 CPU, 1 MB of flash memory, and 512 KB of RAM, the Nordic Thingy:53 will have no problem at all running a machine learning algorithm that has been highly optimized by Edge Impulse Studio for tiny edge computing devices. It also comes standard with a high-quality microphone to capture audio samples, so no additional hardware was needed. And when additional functionality is added in the future to enhance the accident reporting process, the Nordic Thingy:53 also supports several wireless communications protocols to streamline the process.
A neural network classifier was the ideal choice for keyword spotting in this case, so Ravi needed to collect some sample audio clips to train the model to do its job. By installing the nRF Edge Impulse smartphone app, the Nordic Thingy:53 can be linked directly to a project in Edge Impulse Studio, which makes data collection a breeze. After the link is made, data can be collected directly from the hardware’s sensors, then automatically uploaded to the project.
Using this setup, audio from people of different ages, genders, and talking speeds was collected while they spoke the word “accident.” By collecting a diverse dataset, it would be expected that the resulting model would be more robust after training. To reduce the chance of false positives, additional “noise” and “unknown” classes were created using samples from an Edge Impulse audio dataset. Roughly 24 minutes of data was collected in total.
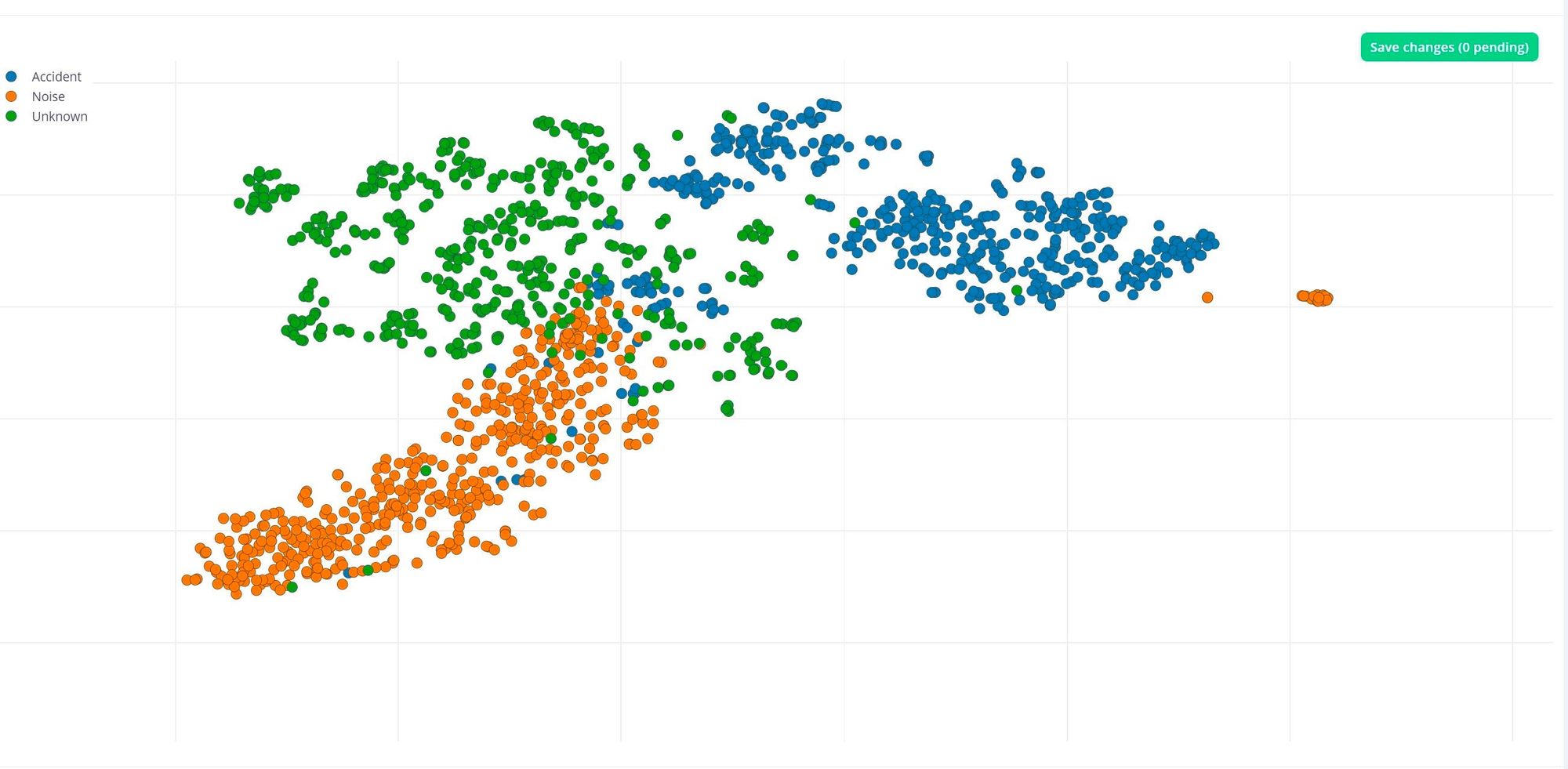
At this point, Ravi used the Data Explorer tool to assess how well the samples assigned to each class clustered with one another. Ideally, each class would be clearly separated from every other class. Examining the results, it was found that this was, by and large, the case. However, some outliers existed, so Ravi dug in deeper on these samples, and found that they were inappropriately split up and the keyword was not fully present in them. Armed with that knowledge, he decided to delete these samples, rather than allow them to mislead the model during training.
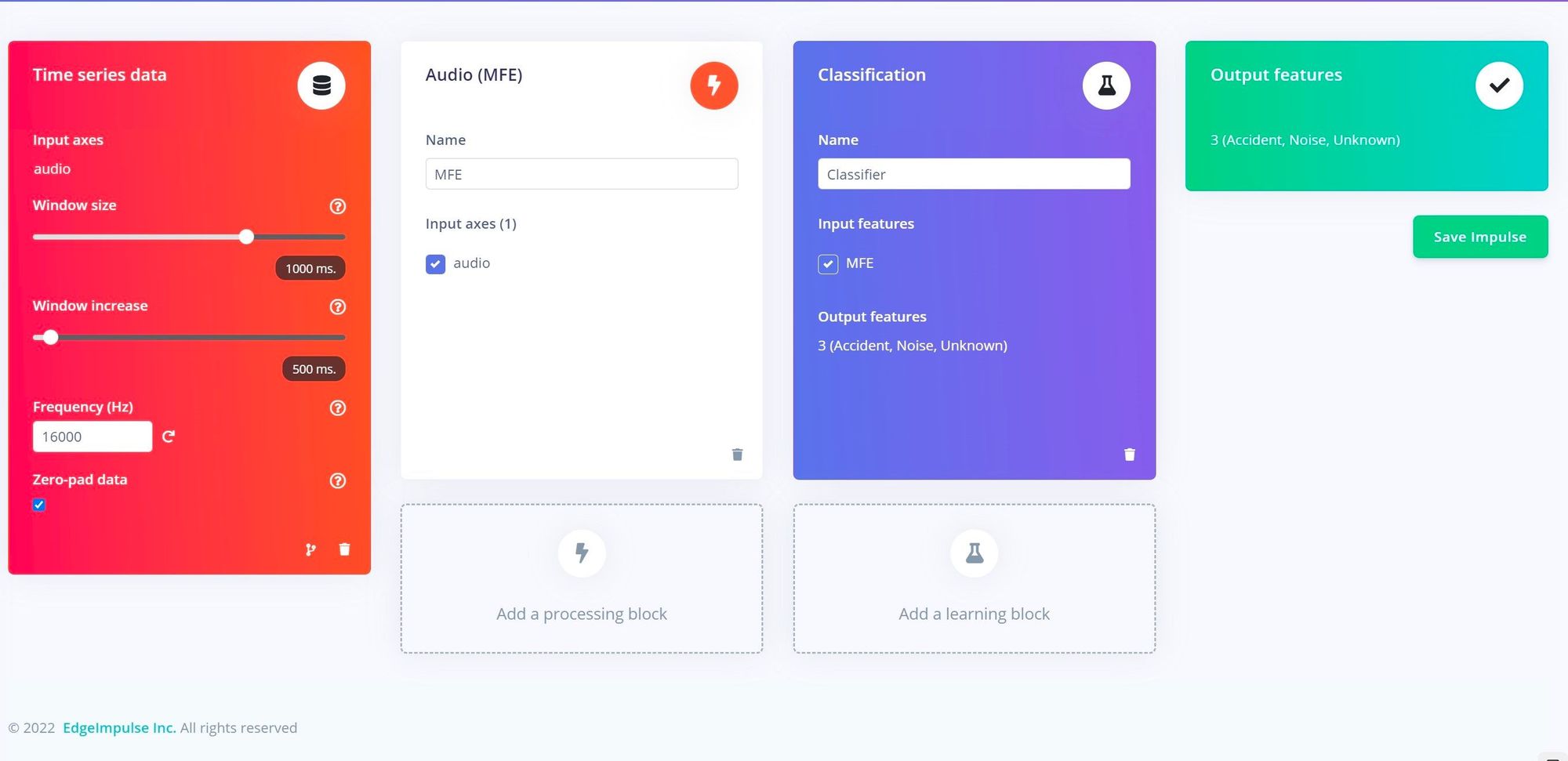
A machine learning classification impulse was designed, beginning with a step to split input audio samples into one second segments. That was followed by an Audio MFE processing block to extract time and frequency features from the signal — this type processing is known to perform very well for keyword spotting applications. The features were then fed into a neural network designed to recognize the keywords it is trained on. While configuring the model’s hyperparameters, Ravi turned on the data augmentation option, which will make very small changes to the training data between cycles to help prevent overfitting to it, and ultimately produce a more robust model.
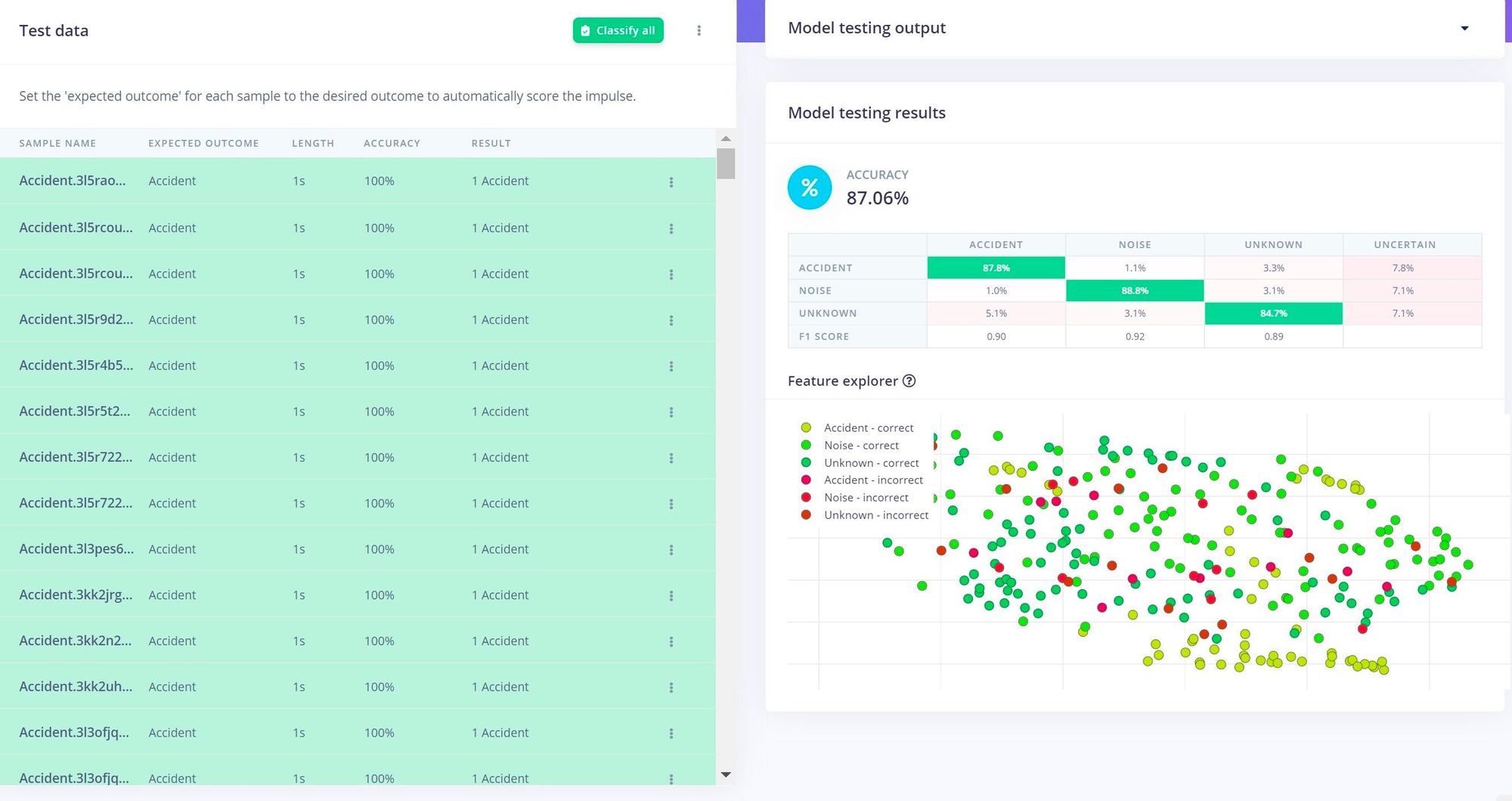
With everything in place, the training process was initiated with a button click. After a short time the results were presented, and it was apparent that all of the validations that were done up to this point had paid off — an average classification accuracy of 94.4% had been achieved. This was further validated using the more stringent model testing tool, and that also showed the model to be performing quite well, with better than 87% accuracy being reported.
The same nRF Edge Impulse app that was helpful during data collection also comes in very handy during deployment. Using the deployment tab, there is an option to build a firmware image and wirelessly transmit it to the Nordic Thingy:53. This step enables the full classification pipeline to run on the physical hardware. This is especially important when working with a microphone. If continuous streams of audio needed to be transferred to the cloud, it would raise significant privacy concerns.
Using the same app, Ravi was able to see the inference results during a series of real-world tests. He found the device to be working exactly as intended, accurately detecting when the word “accident” was spoken. Now he has his sights set on building on top of this prototype to create a more full-featured system for worker accident reporting. But there is no need to wait — read up on the project documentation, then clone the public Edge Impulse Studio project, and you will have a serious head start in building your own, custom solution.
Want to see Edge Impulse in action? Schedule a demo today.