
Between the supply chain issues and shifting customer preferences of the past two years or so, unwanted inventory has been piling up on the shelves and in the warehouses of retailers around the world. Orders had to be placed much earlier than usual to try and keep up with increasing demand, so purchasers had to predict what consumers would want when those orders finally came in, perhaps nine to twelve months later. As it turns out, retailers cannot predict the future better than any of the rest of us, and there is a lot of inventory out there that is not exactly flying off the shelves. One consequence of this situation is that it has been made crystal clear that retailers need effective and accurate inventory management solutions.
Whether the goal is to determine the items that should be sold at a deep discount to make room for new stock, to ensure that desirable items do not become unavailable, or to create a better plan for future purchasing patterns, the first step is to get an accurate accounting of the present inventory. This task is frequently handled by humans that visually inspect and count items. But manual counts are labor intensive, slow, error prone, and challenging to keep up-to-the-minute. These shortcomings have an impact on purchasing schedules, and that can lead to lost sales and poor customer satisfaction. Of course there is always room for improvement in any process, and engineer Shebin Jose Jacob believes that he has a better way for retailers to manage their inventory.

Rather than a manual process, Jacob has developed an automated solution that leverages computer vision and a machine learning algorithm developed with Edge Impulse Studio that continuously watches the products on a shelf, and immediately updates an inventory database as items are added or taken away. Having real-time information allows this proof of concept system to send an alert as soon as an item falls below a certain level of availability so that more can be ordered. As data is collected over time, the device will also give management insights into consumers’ shopping trends. Altogether, this system provides the information needed to help avoid inventory mismanagement disasters like those that many retailers are now dealing with.
Jacob wanted to ensure that his device would be accessible to retailers both large and small, and that it could be deployed widely enough to cover entire stores and warehouses, so he chose inexpensive hardware that can be deployed virtually anywhere. The powerful Raspberry Pi 4 single-board computer, with a quad core Arm Cortex-A72 processor running at 1.5 GHz, and up to 8 GB of RAM was selected to run the machine learning algorithm. It was paired with a five megapixel Raspberry Pi Camera V1.3 to capture images for analysis. The hardware was housed in a commercial case designed for the Raspberry Pi.
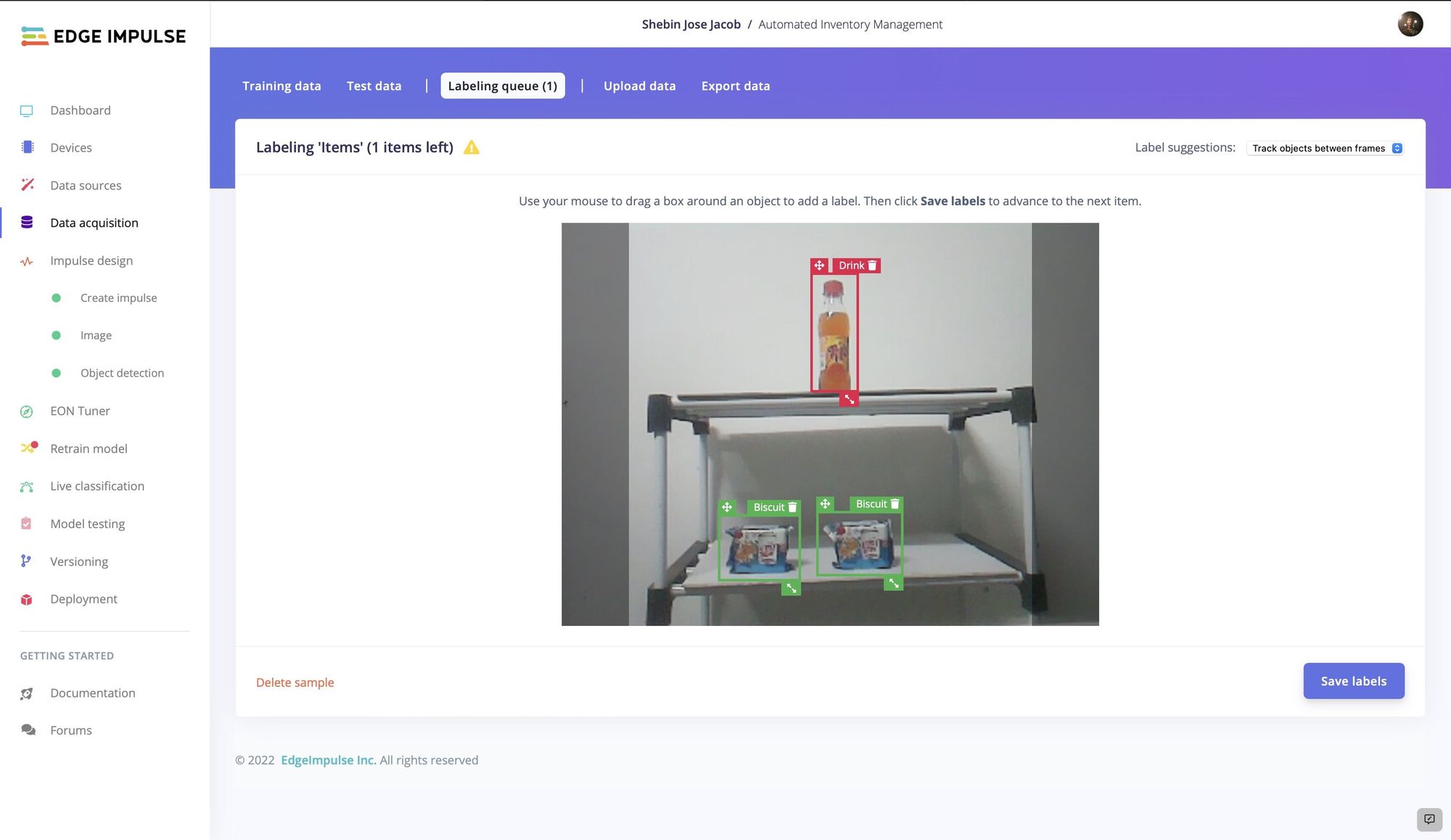
To be able to recognize multiple objects in a single image frame, an object detection model was needed. But before building that model, sample images would be needed to train it. To make the data collection process as seamless as possible, the Edge Impulse CLI was installed on the Raspberry Pi. This links the device to a project in Edge Impulse Studio, and as sensor data — from a camera in this case — is captured, it is automatically uploaded to that project. Jacob installed his prototype device facing a shelving system that he placed items on in different locations, and in different orientations. As images of this setup were captured, they were transferred to Edge Impulse.
To prove the concept, two classes were initially chosen for demonstration purposes — “drink” and “biscuit.” The labeling queue tool was used to draw boxes around each item so that the model would have the information that it needed to learn what they look like. Since the labeling queue is an AI-assisted tool, it will do most of the work on its own. After the first few boxes are drawn, they will be automatically drawn for subsequent samples. All that is needed is to verify that the prediction is accurate, or make a small tweak to the box if a little adjustment is in order.
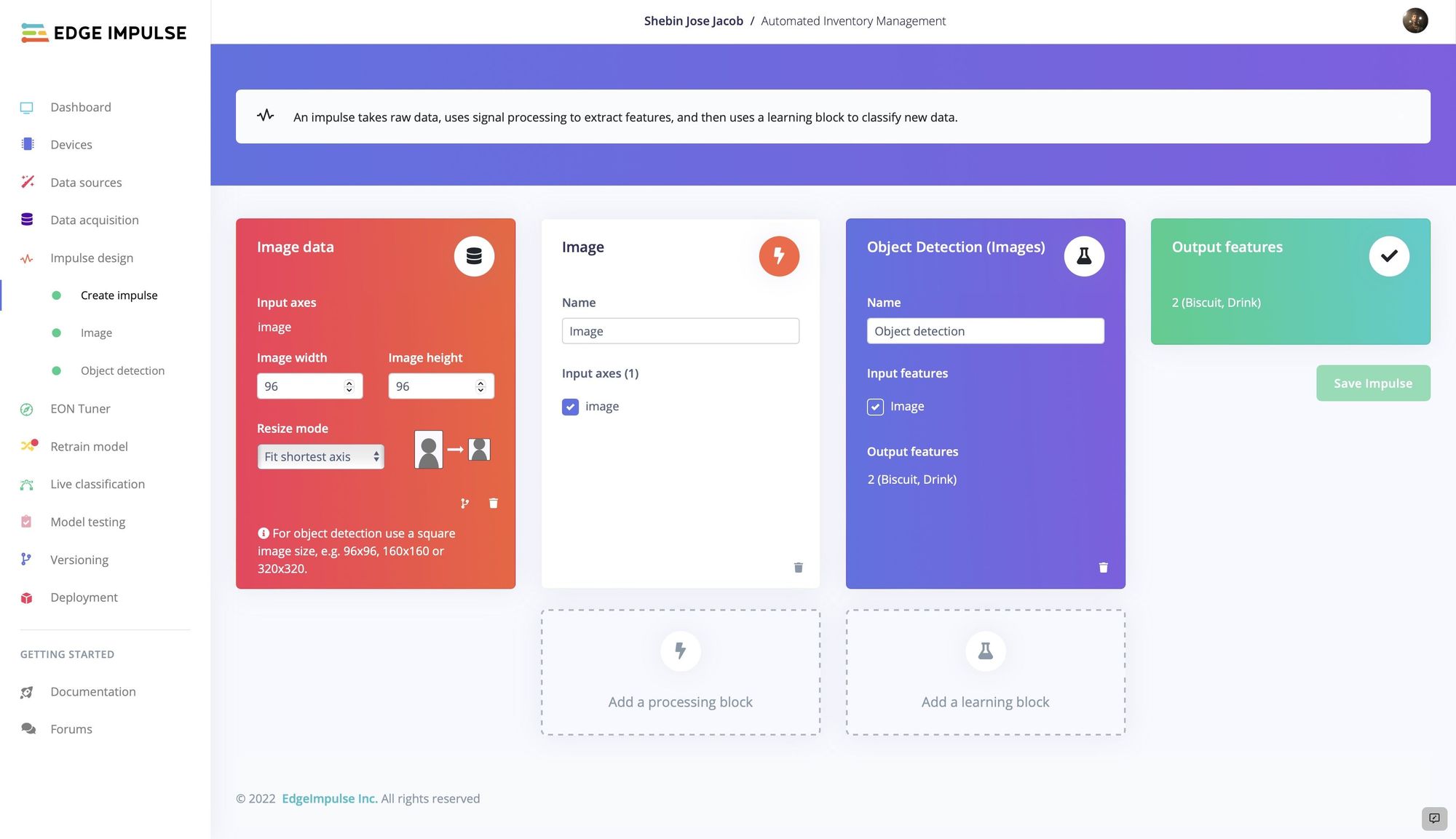
With a training dataset waiting in the wings, Jacob started designing the impulse that would analyze it. A preprocessing step was added to shrink the images to 96 x 96 pixels — this has the effect of reducing the amount of computational resources that are required later on. Next, a step was added to extract the most relevant features from the image data and forward them on to the machine learning model. Edge Impulse’s ground-breaking FOMO object detection algorithm was selected because it is both very accurate and highly optimized for running on edge computing platforms with minimal computational resources available. The algorithm was designed to detect drinks or biscuits, but that list could be made much larger and more specific by simply supplying a larger, more diverse set of training data.
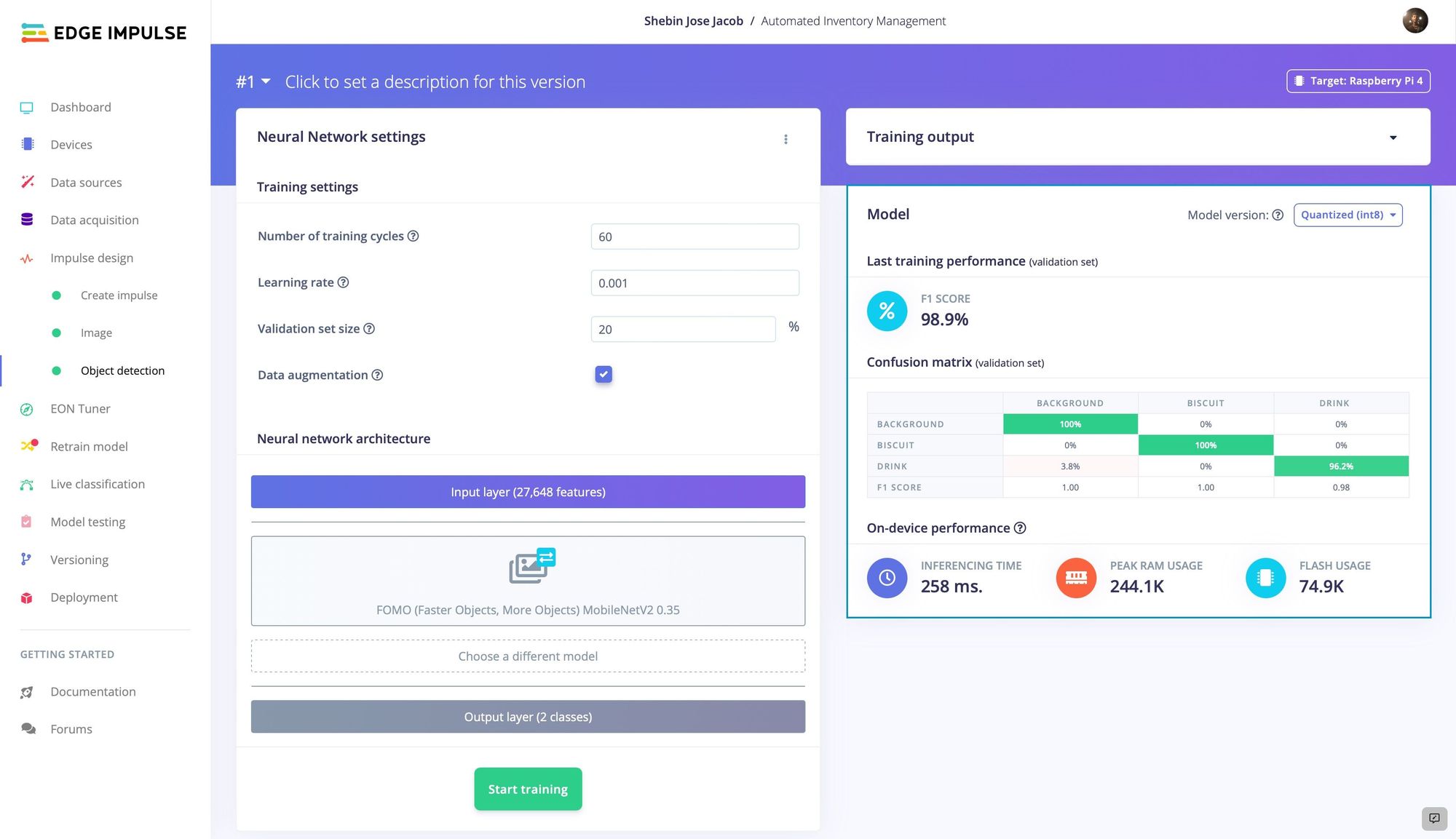
The training process was kicked off, and after a short time the results were presented to help assess how well the model was performing. The model achieved an F1 score of 98.9% right off the bat, indicating that it was highly accurate at detecting the objects it was trained to recognize. Since very high accuracy measurements can be a sign of model overfitting, Jacob also ran the more stringent model testing tool that makes use of a dataset that was excluded from the training process. This test revealed an accuracy rate of 100%, so there was nothing left to be further tuned.
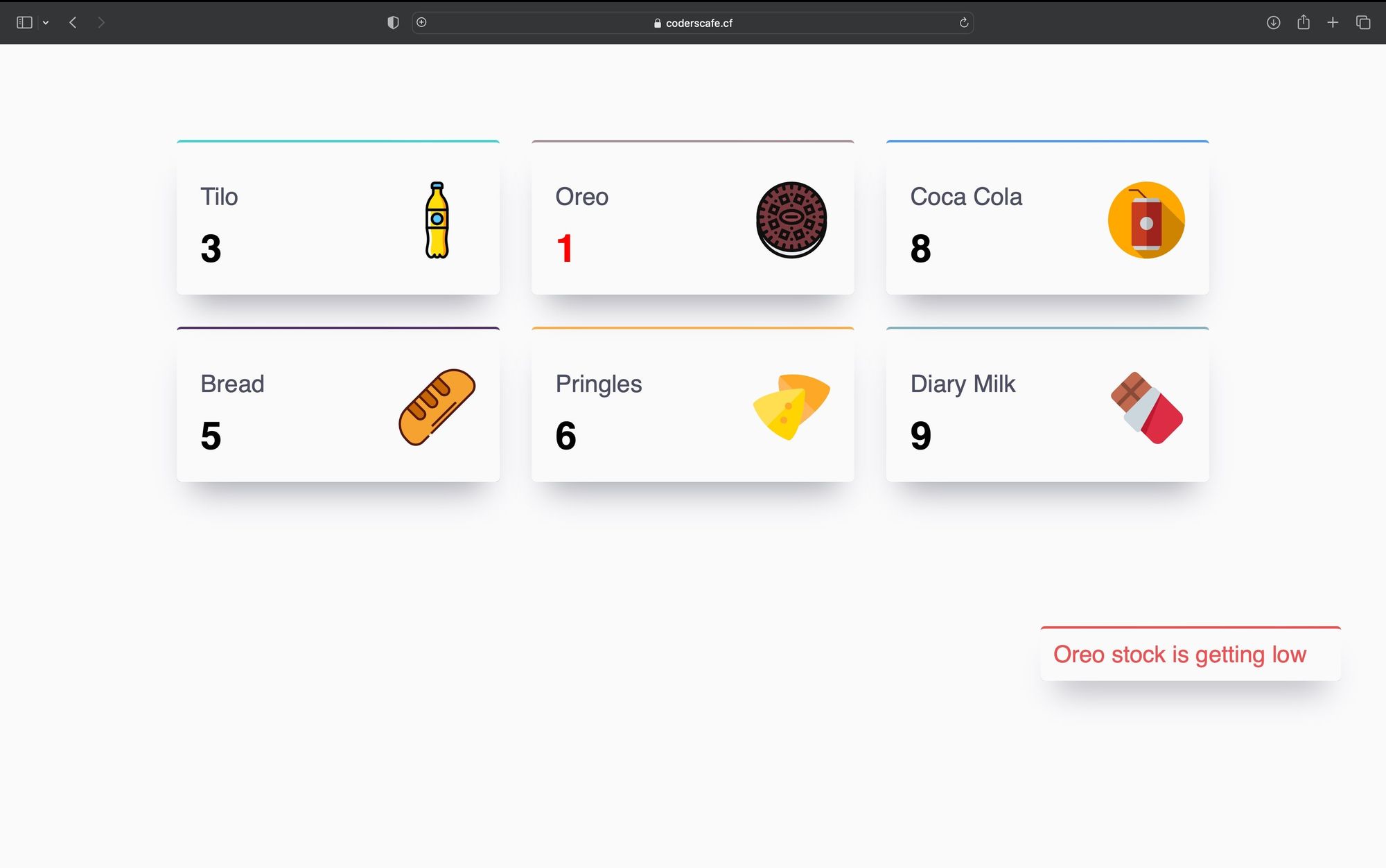
To put the finishing touches on the project, Jacob created a database to store the results of the model inferences. A web application was then developed, which was driven by the data stored in the database. This simple web dashboard gives a quick, concise view of everything presently in inventory. It also shows alerts when inventory of a particular item is getting too low.
To be certain, a good deal more training data would need to be collected before this device would be of use in the real world, but the methods would otherwise not need to change. The payoff that would come for years to follow in the form of lower costs and better inventory management is likely worth that upfront effort for many retailers, especially considering present conditions. Jacob has provided a nice write-up of his work for anyone interested in learning more.
Want to see Edge Impulse in action? Schedule a demo today.