
Since the launch of Edge Impulse developers have been able to use sensor data to make sense of the real world through classification (’which one of these states is happening right now’) and anomaly detection (’is what’s happening out of the ordinary’) models. Today, we also add the ability to predict scalar values through the new regression learning block. With the new regression block you can predict the future (’what will the temperature be 60 minutes from now?’) and solve problems that don’t fit into set classes (’how much water is flowing through a pipe?’).
Want to immediately see regression in action? See our example project.
Unlike classification models that give a confidence per category (e.g. 90% confidence that I hear water, 10% confidence that I hear noise), regression models output a number (e.g. 1L of water per minute flowing through a pipe). This is incredibly useful for problems that don’t fit in a set category. If you’re building a cold chain monitoring system it’s useful to have a category ’confidence that the temperature rises >9 degrees within the next 60 minutes’ (classification), but it’s even more useful to continuously predict the temperature 60 minutes from now - and thus have much finer grained control over your alerts.
Regression can also be used to create synthetic sensors (train with 4 sensors, deploy with 3 sensors, and use regression to predict the values of the fourth one), estimate the number of people or animals walking past using vibration or audio data, or predict the weight of a walking sheep (a real customer use case!).
Sounds interesting? Here’s how you get started with Edge Impulse!
Building regression models
To build a regression model you collect data as usual, but rather than setting the label to a text value, you set it to a numeric value. For example, for the cold chain monitoring system mentioned above you 1) collect raw temperature data, and 2) use the temperature 60 minutes later as the label.
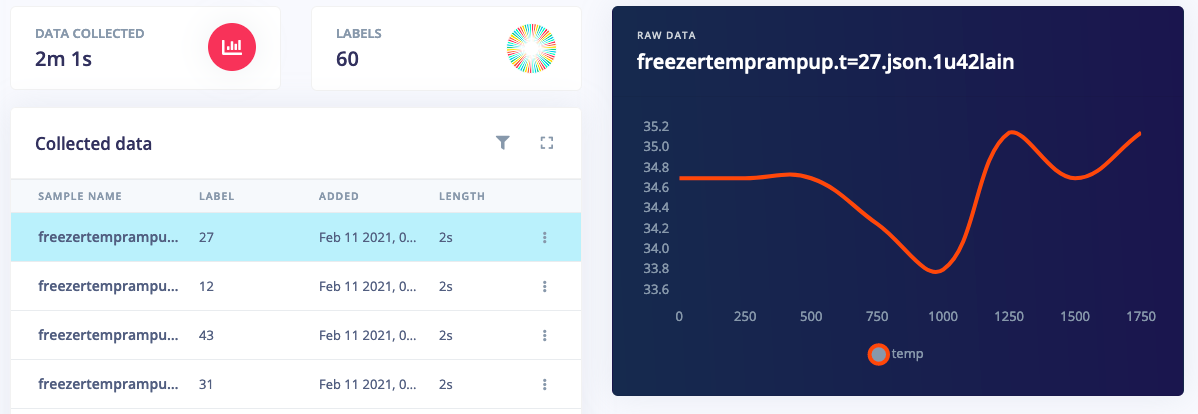
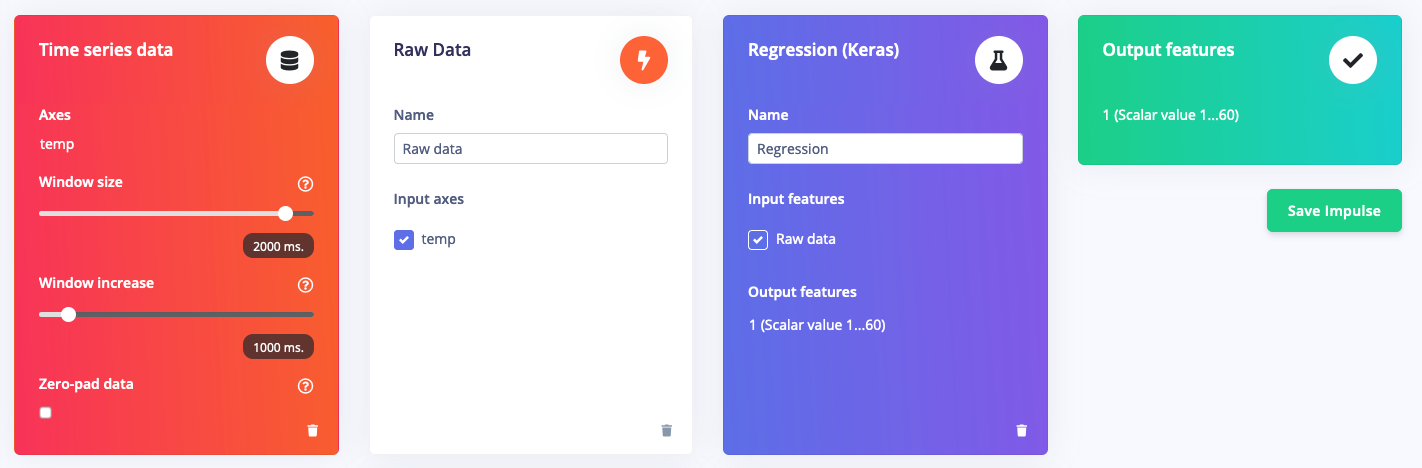
From there you build your impulse as you always do. You can use any of the built-in signal processing blocks to preprocess your vibration, audio or image data, or use custom processing blocks to extract novel features from other types of sensor data - and then select a ’Regression’ learning block to learn from this data.
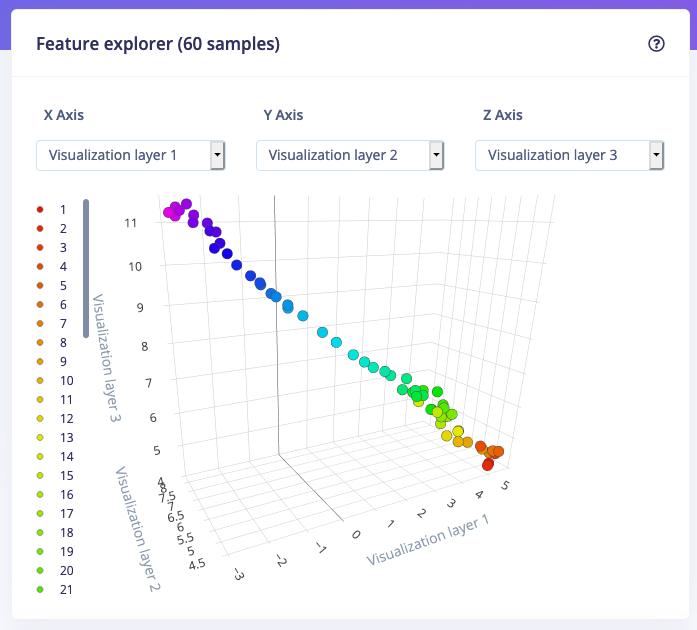
To make it easy to validate whether your data separates well, the feature explorer has been updated and now color codes your data according to the label. If you see a rainbow, then that’s good news.
Then, to train your model, head to the ’Regression’ page, and hit Train.
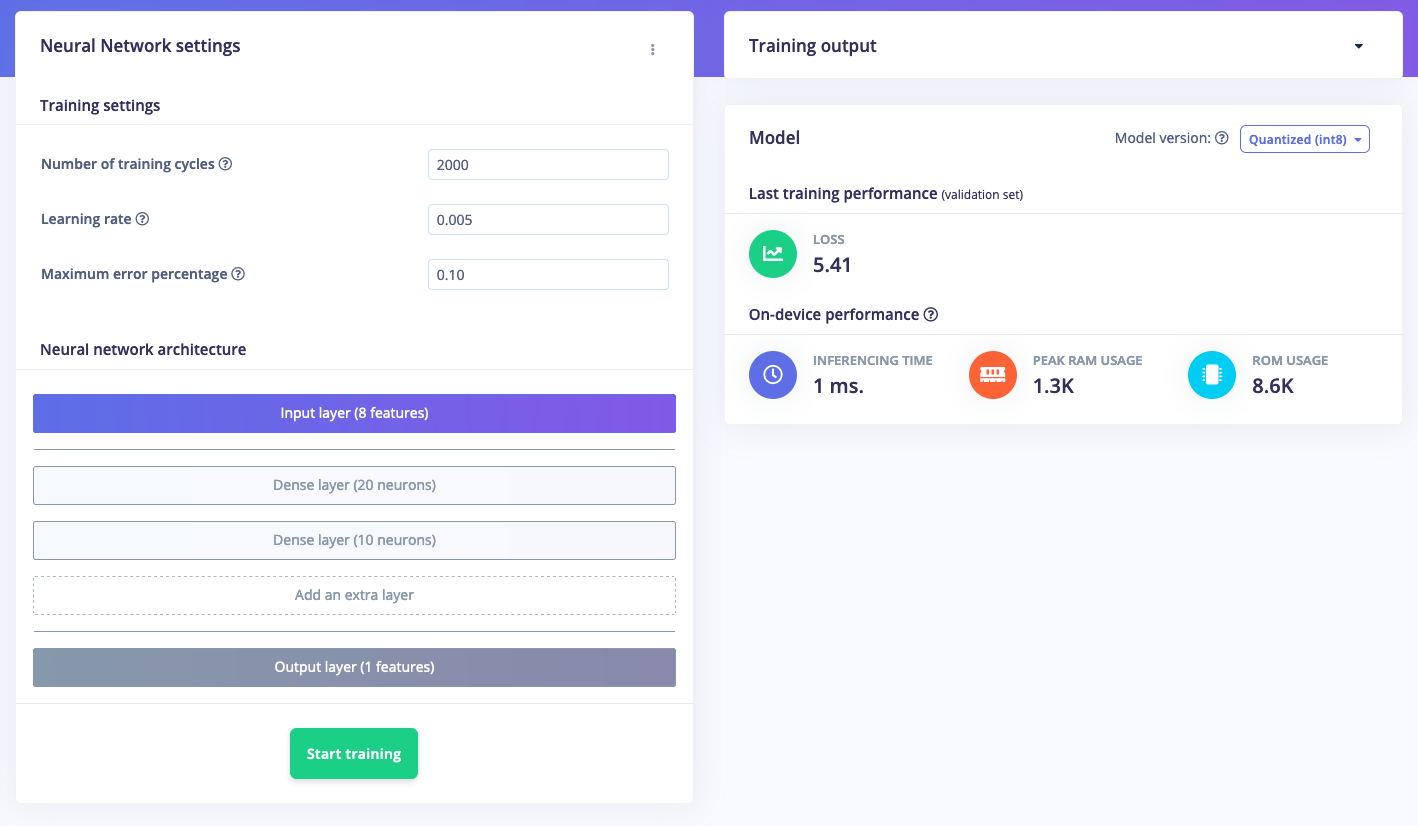
As usual, the performance characteristics are shown, and you have full freedom in modifying your neural network architecture - whether visually or through writing Keras code. That’s it. You now have a trained network.
Deploying back to device
Deploying the trained model back to a device is as easy as always. If you have a fully supported development board, just head to the Deployment page and deploy a model directly - otherwise, head to Running your impulse locally for instructions on exporting your model as source code so you can integrate the model directly in your firmware. Regression models are compatible with EON and use full hardware acceleration on most targets, making it feasible to run these models in realtime on the smallest of devices. Naturally, regression models are also compatible with Edge Impulse for Linux.
Recap
Regression models are a great addition to Edge Impulse, as they allow you to solve a complete new class of problems using machine learning. Regression blocks are fully compatible with all processing blocks, making it much easier to pre-process and clean up complex and high-resolution sensor data; and you can combine regression blocks with other learning blocks, f.e. to run both anomaly detection and regression at the same time.
Questions? Project ideas? We’d love to hear what you’re going to build with the new regression block on the forum!
Jan Jongboom is the CTO and cofounder of Edge Impulse. He loves graphs and rainbows.