
When developing Edge AI applications, every kilobyte of RAM is a precious resource. With this in mind, we're introducing an additional feature that directly addresses a common challenge faced by developers: reducing memory usage for edge AI models. We are happy to announce a new optimization option when exporting your models, the EON Compiler (RAM optimized). This EON Compiler (RAM optimized) is an additional option on top of our traditional EON Compiler. It is available for Enterprise customers.
The Edge Optimized Neural (EON) compiler is a powerful tool, included in Edge Impulse, that compiles machine learning models into highly efficient and hardware-optimized C++ source code. It supports a wide variety of neural networks trained in TensorFlow or PyTorch - and a large selection of classical ML models trained with scikit-learn, LightGBM or XGBoost. The EON Compiler also runs far more models than other inferencing engines, while saving up to 65% of RAM usage.
What this means for professional developers
For engineers and developers, this optimization opens up new possibilities. Lower RAM usage means that AI models can run on smaller, less expensive MCUs, enabling you to design and launch more competitive products in the market.
How does it work?
The traditional implementation, computed layer by layer, necessitates storing the intermediate results, which increases the RAM requirements. By analyzing our machine learning architectures, we identified that most of the RAM usage is used to store these intermediate results. Inspired by this, we devised a method to compute values directly as required, thus minimizing the need to store these results. This approach led to a substantial decrease in RAM usage, for a slightly higher latency or size (ROM) cost.
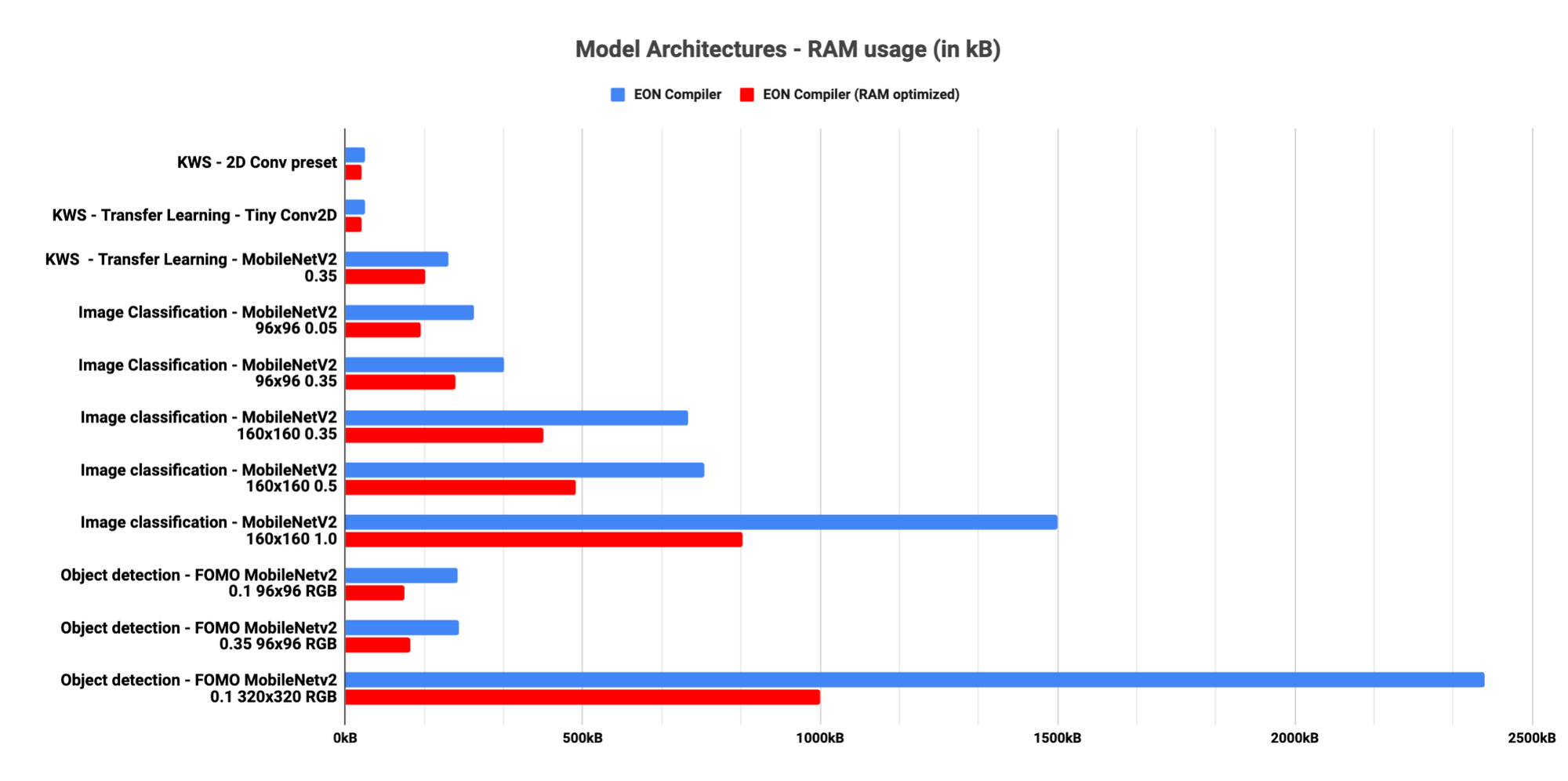
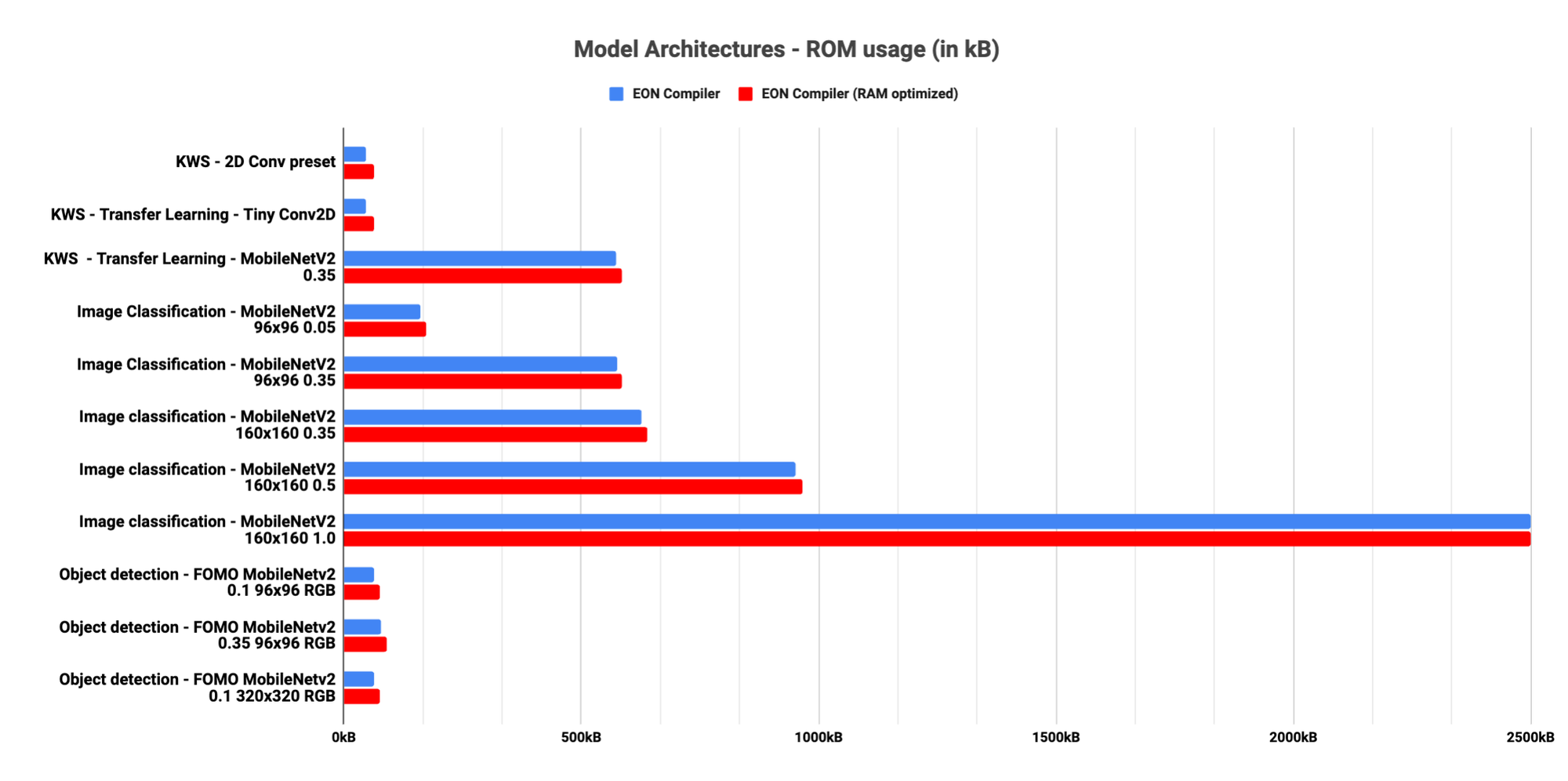
In practice, we demonstrated this with our default 2D convolutional model for visual applications. By slicing the model graph into smaller segments, we managed to reduce the RAM usage significantly — by as much as 40 to 65% compared to TensorFlow Lite — without altering the accuracy or integrity of the model's predictions.

See the documentation for more information and metrics.
Looking ahead: Practical implications and future work
Our focus remains on providing user-friendly and advanced tools for professional engineers. With the EON Compiler (RAM optimized), we’re taking a step further and offering new possibilities to design and optimize AI models on edge devices. We're also exploring further optimizations and intelligent algorithms based on specific device capabilities and developer preferences.
If you want to use the EON Compiler (RAM optimized) in your Edge Impulse project or need help building a solution for your particular application, please contact us for enterprise pricing.