
In computer vision, the term (local) features designates interesting areas of the image. These areas can correspond to contours, points or regions of interest. Each feature detected is associated with a vector, called a feature descriptor or feature vector, which, as its name suggests, describes the area concerned. In short, a good feature must be unique enough to be able to differentiate two different classes of images, and generic enough to be able to easily recognize images of the same class despite the diversity of representations.
There are two ways of finding the right features to use. One is to let the neural network handle this, and this often works great, the other is to use preprocessing techniques. Neural networks are great at generalizing this on unknown datasets, but if you are already knowledgeable in computer vision, the following approach can speed the process and give astonishing results.
The default pipeline in Edge Impulse is to let the neural network do this, but you can use custom processing blocks to run a CV algorithm first - this can lead to smaller models (as the neural network does not need to find these CV rules itself). In this article, we will discover why and how to use the second option to extract meaningful features for your projects.
Several techniques exist to pre-process the images, you can find in this Google Colab Notebook, some of the following examples such as binary thresholding, Canny filters for edge detection or Harris filters for corner detection:


As an example we will use the “edge detection” technique to preprocess the image and extract meaningful features to pass them along to the neural network. The custom processing block we are using is open source and can be found under Edge Impulse’s GitHub organization.
If you are interested in knowing more about how to create a custom processing block, we invite you to read our documentation on this topic. And do not hesitate to share your custom processing block with the community too!
Edge detection
The edges provide a lot of information about an image: they delimit the objects present in the represented scene, the shadows or the different textures while removing unnecessary information. This is why it is a good try to use this preprocessing technique for your image projects.
One way to detect edges would be to segment the image into objects, but this is a more difficult problem. The Canny filter solution, developed in 1986 by John Canny at MIT, is based on the study of the gradient and is both a simpler solution to set up and less consuming in computing resources.
To give a general understanding, the edges are in the regions of the image that show strong changes. The edges of the objects correspond to changes in depth (we go from one object to another located in the background) and the shadows and different textures correspond to changes in illumination.
Mathematically, the detection of the edges is therefore to seek the points of the image where the intensity function "I" varies abruptly. However, we know that a high amplitude of the gradient indicates a strong change in intensity. The goal is therefore to find the local maxima of "|| ∇I ||".
We won’t spend too much time into the mathematical aspects of this process because in the end, what interests us is the result of this preprocessing and luckily for us, the Canny filters are easily available in many image processing libraries.
Custom processing blocks in Edge Impulse Studio
To use your own custom processing block in the studio, it needs to be exposed publicly on the internet. See Exposing the processing block to the world to expose it from your computer using ngrok.
To add your freshly created and exposed processing block to your Machine Learning pipeline, simply navigate under the “Create Impulse” page in your project and make sure your custom block is accessible by the studio: a green badge informs you if we successfully reached your exposed processing block.
Then, in the following view, you can adjust the threshold parameters by looking at the results at the “DSP results”. Feel free to change the item you want to visualize on the upper right corner:
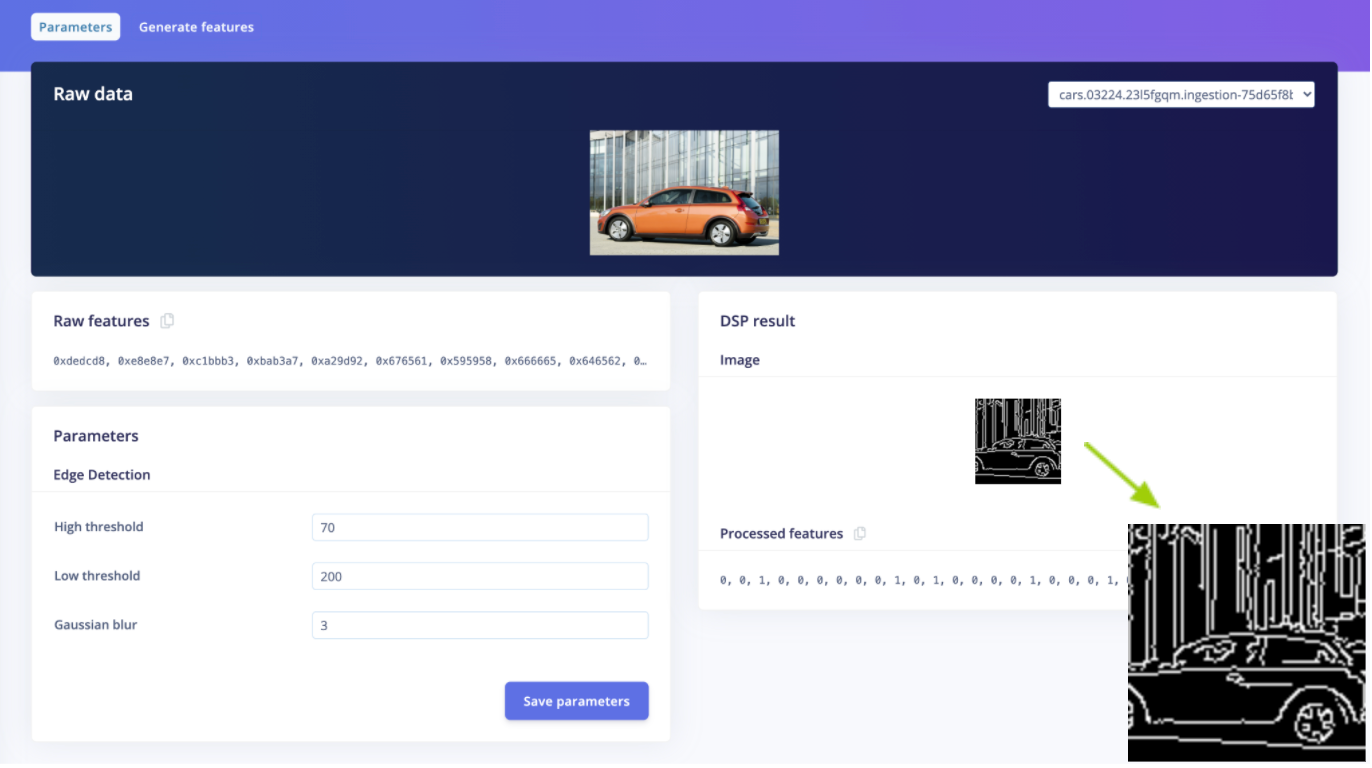
Once happy with your settings, save the parameters and generate the features.
In this project, the results are mind-blowing as you can see below. We can clearly distinguish two separated clusters (left image) compared to the raw image processing block (right image).
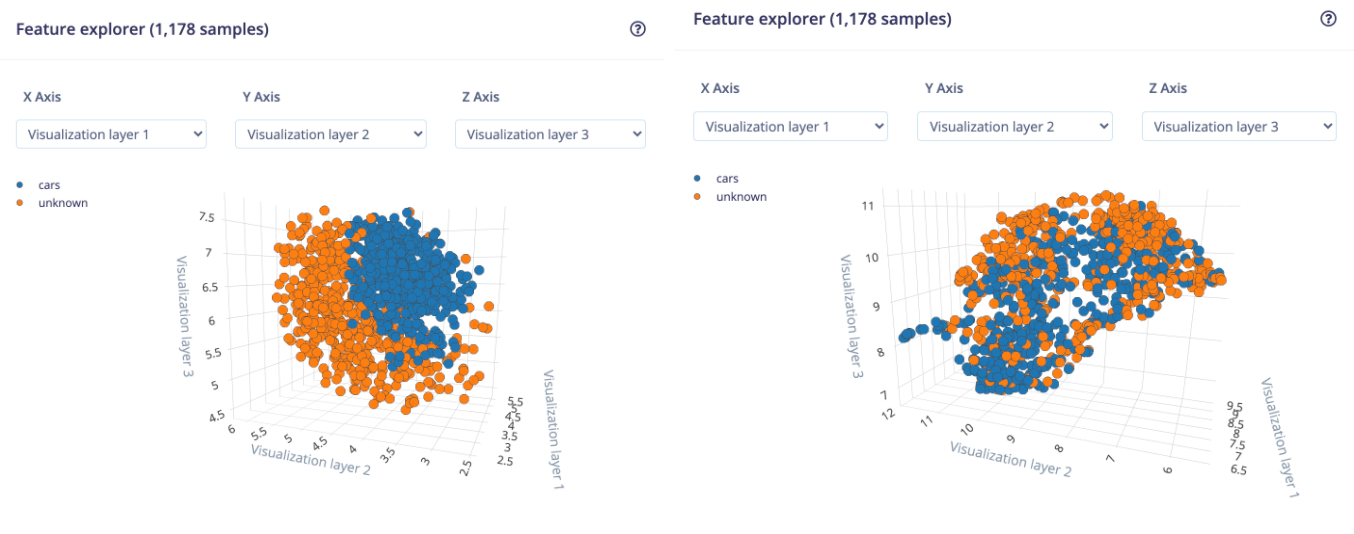
This cluster separation should ease the learning process in the next step.
As a comparison, here are the results when using the default pipeline, raw image processing block + Transfer Learning (with the smallest model available, MobileNetv1 0.01):
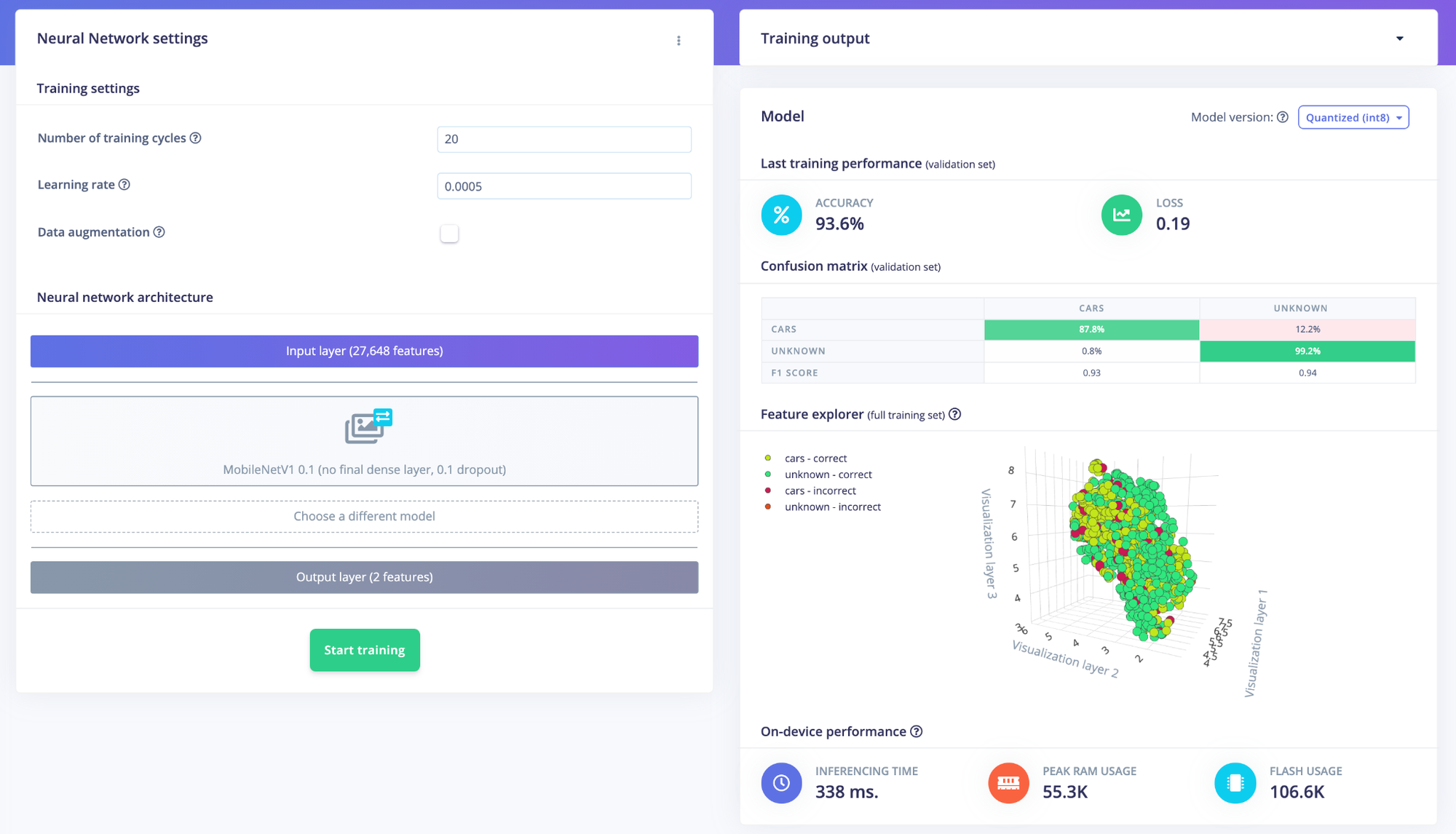
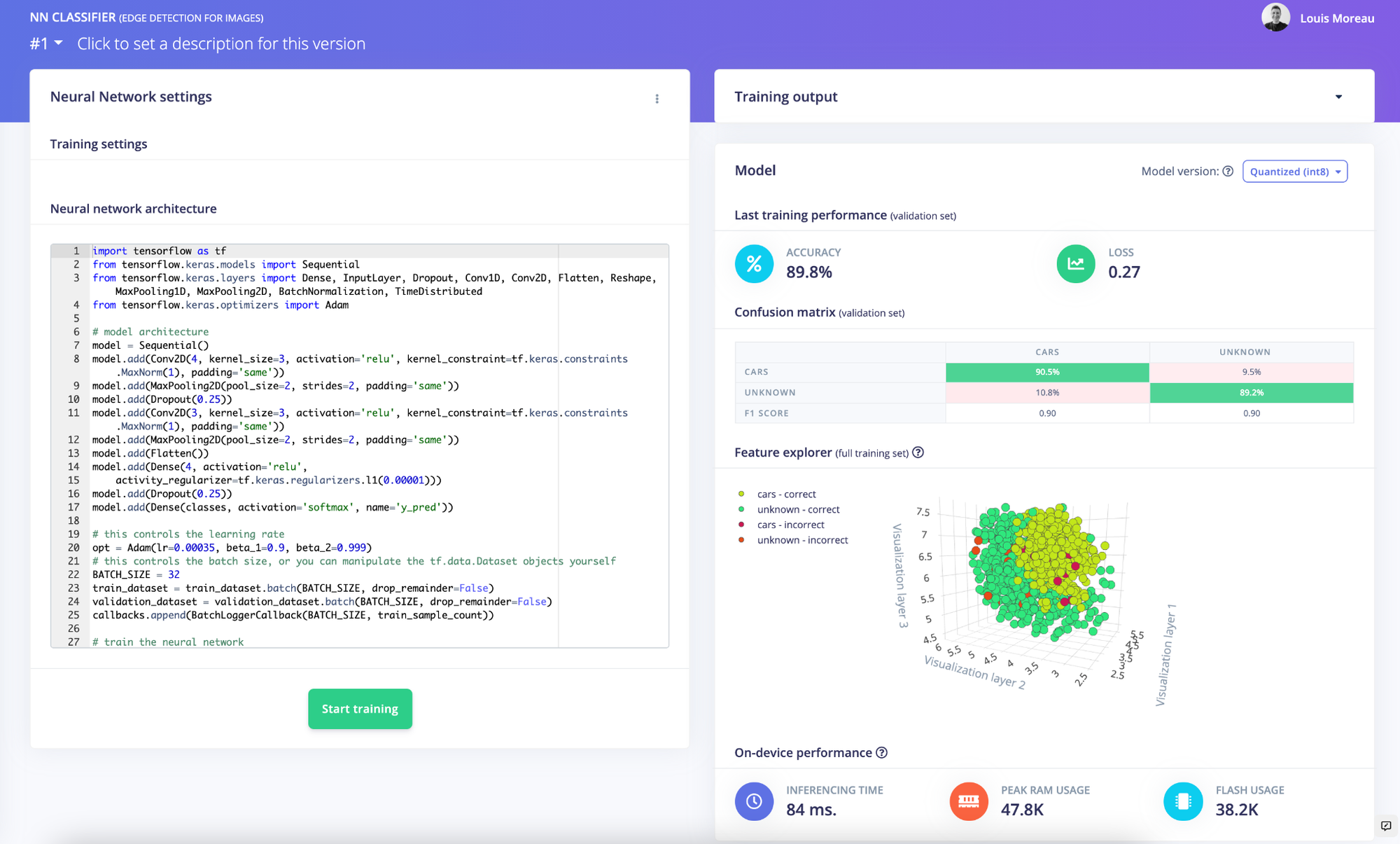
In this specific case, preprocessing your images with our edge detection processing block before training the NN gives a 89.9%-accuracy vs a 93.6%-accuracy with the default pipeline. However, our model runs 4x faster on embedded targets while consuming less RAM and ROM.
As in every embedded machine learning project, you will have to decide on the tradeoff between accuracy and resource constraints according to your specific needs.
Running on device
When it comes to running your custom processing block on the device, your custom block behaves exactly the same as any of the built-in blocks. You can process all your data, train neural networks or anomaly blocks, and validate that your model works. However, we cannot automatically generate optimized native code for the block, like we do for built-in processing blocks, but we try to help you write this code as much as possible. When you export your project to a C++ library we generate struct’s for all the configuration options, and you only need to implement theextract_custom_block_featuresfunction.
Conclusion
With good feature extraction you can make your machine learning models smaller and more reliable, which are both very important when you want to deploy your model on embedded devices. With custom processing blocks you can now develop new feature extraction pipelines straight from Edge Impulse, whether you’re following the latest research, want to implement proprietary algorithms, or are just exploring data.