
Smoke detectors are a critical part of any fire safety system today. With new standards being rolled out for both residential and commercial smoke detectors, the requirements that fire safety products must comply with have become even stricter. Smoke detector manufacturers must now face challenges like detecting fires earlier, reducing false alarms for nuisance smoke such as that found in cooking, and more. Machine learning, but specifically at the edge, may prove useful to addressing these challenges as it allows inference to be performed with minimal latency and low power consumption, two key aspects of any robust smoke detector design.
Machine learning on the edge also brings new capabilities to existing hardware. Using their own datasets, smoke detector manufacturers can train high accuracy machine learning algorithms, which can then be a part of a firmware upgrade deployed to products in the field or even products that are about to leave the manufacturing floor. In cases like this, no hardware rework is necessary.

This demo shows a proof of concept of how machine learning can be used to differentiate between types of smoke: true smoke, smoke from cooking, and no smoke.
For this demo we perform sensor fusion with TVOC, CO2 and humidity sensors. The sensors used here can also be easily swapped out for sensors typically used in smoke detectors such as photoelectric and ionization sensors. With a sufficient data set, we would expect similar levels of accuracy to the model trained in this demo.
For this demo, we use the SparkFun Environmental Combo Breakout — which combines CCS811 and BME280 sensors — in association with the Himax WE-I Plus board to run the inference; however, any Cortex-M0+ or higher performance MCU can be employed as the main processing unit.

The source code used to collect data and run the inference can be found on GitHub.
We have collected around three minutes of training data for our different classes: true smoke (generated by a canned smoke detector tester spray), smoke from cooking meat (nuisance smoke) and no smoke (or ambient). New data points are collected every 500ms from the sensors.
Below are some sample extracts from the three classes:
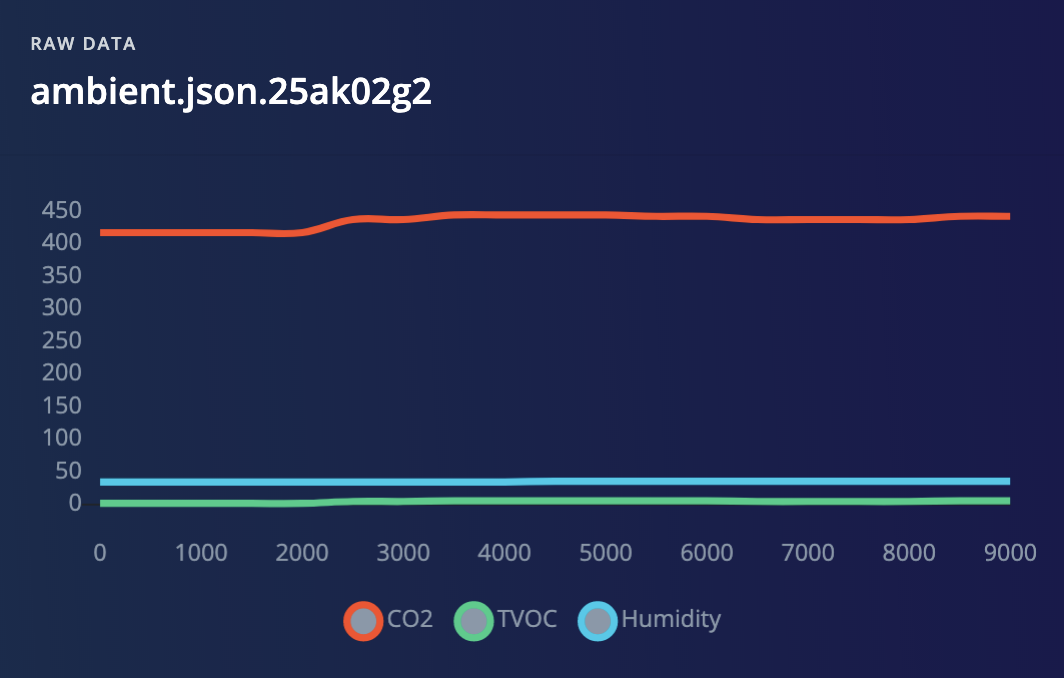
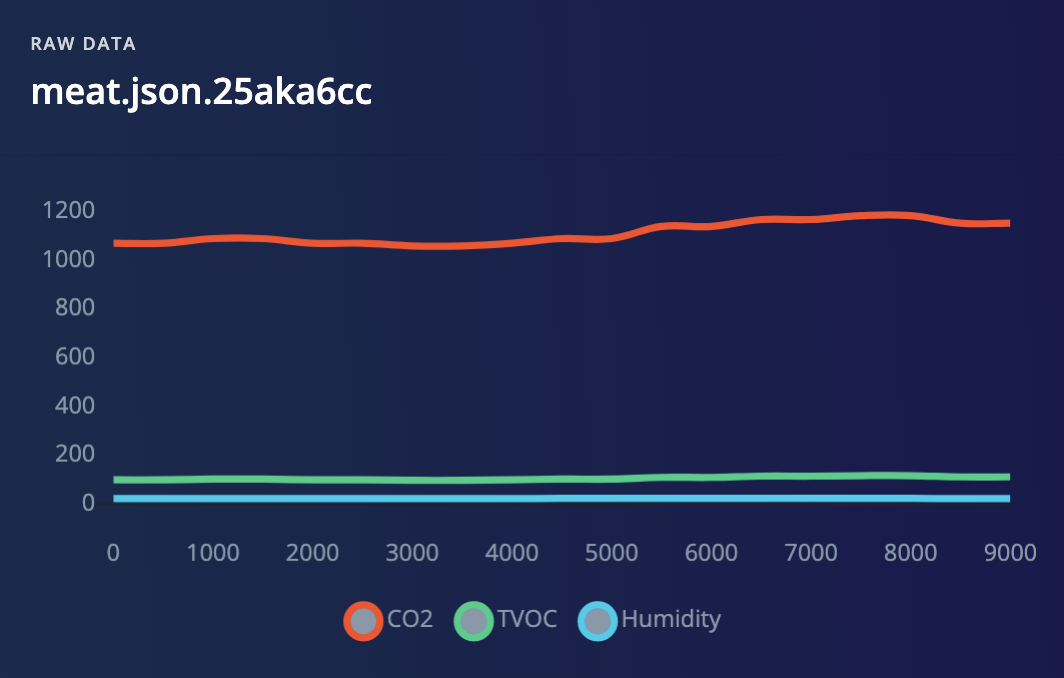
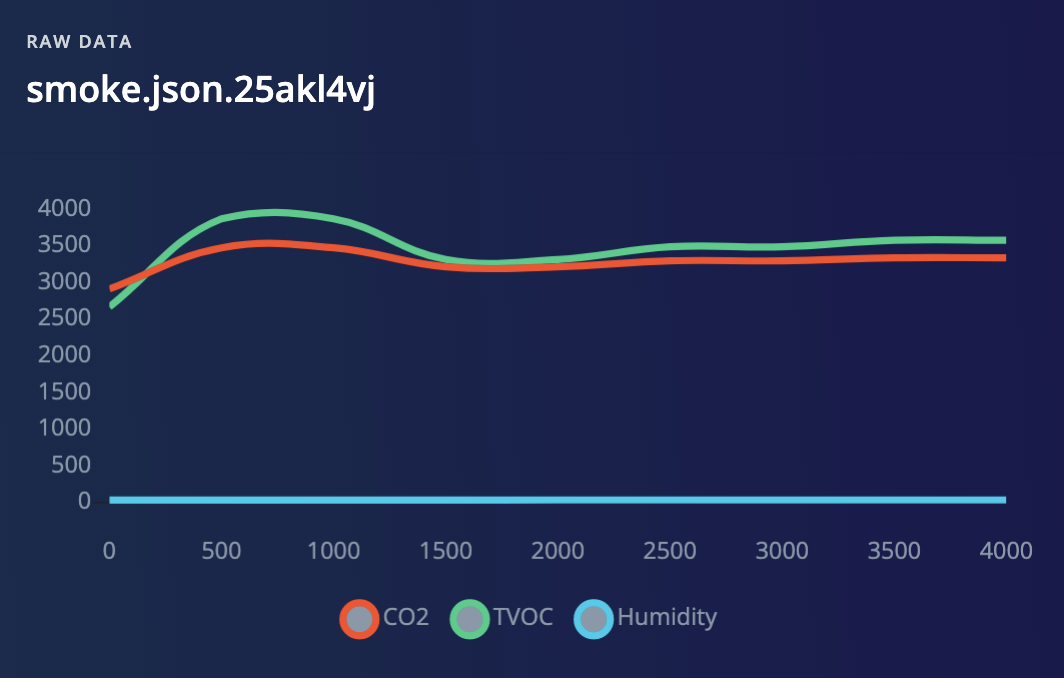
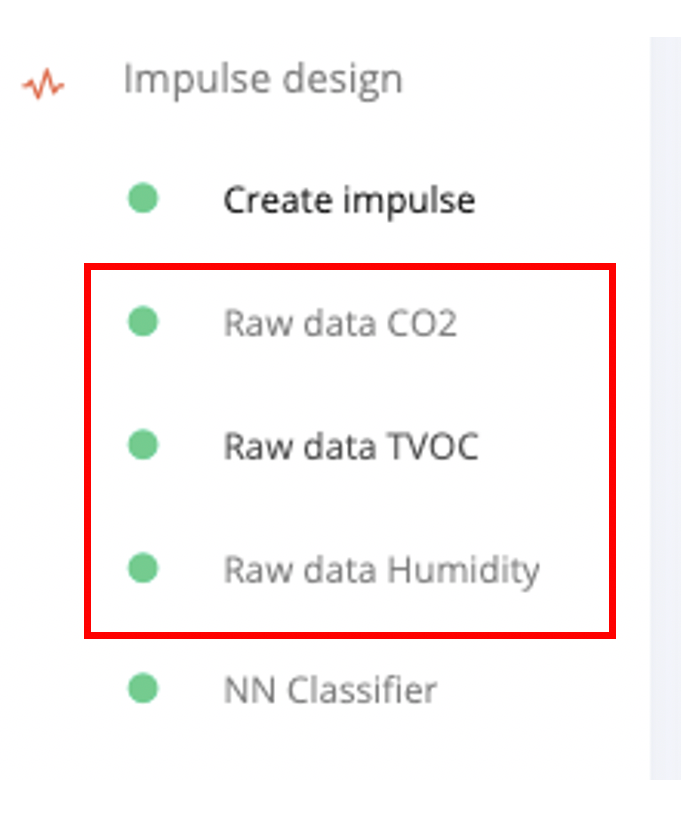
To design our impulse we use three different raw data blocks to normalize values of each sensor to the range [0 - 1], as neural networks perform better on normalized data:
Normalized data is then fed into a two-layer Dense Neural Network. Even with our limited number of samples, we reach a 100% training accuracy:
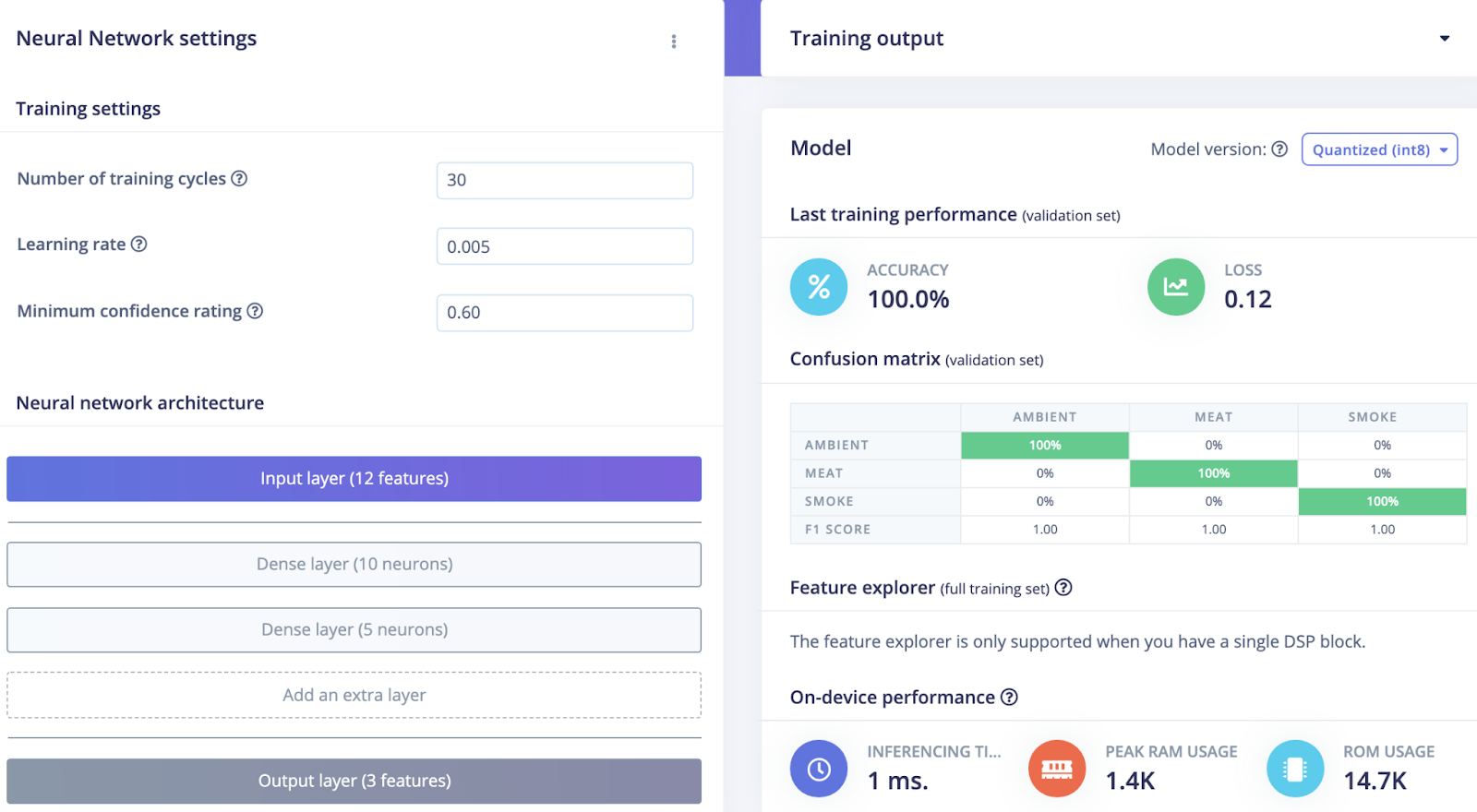
We have also collected additional data for our test set to validate our neural network performances and check any potential overfit issues. As for the training data, we achieve a 100% accuracy:
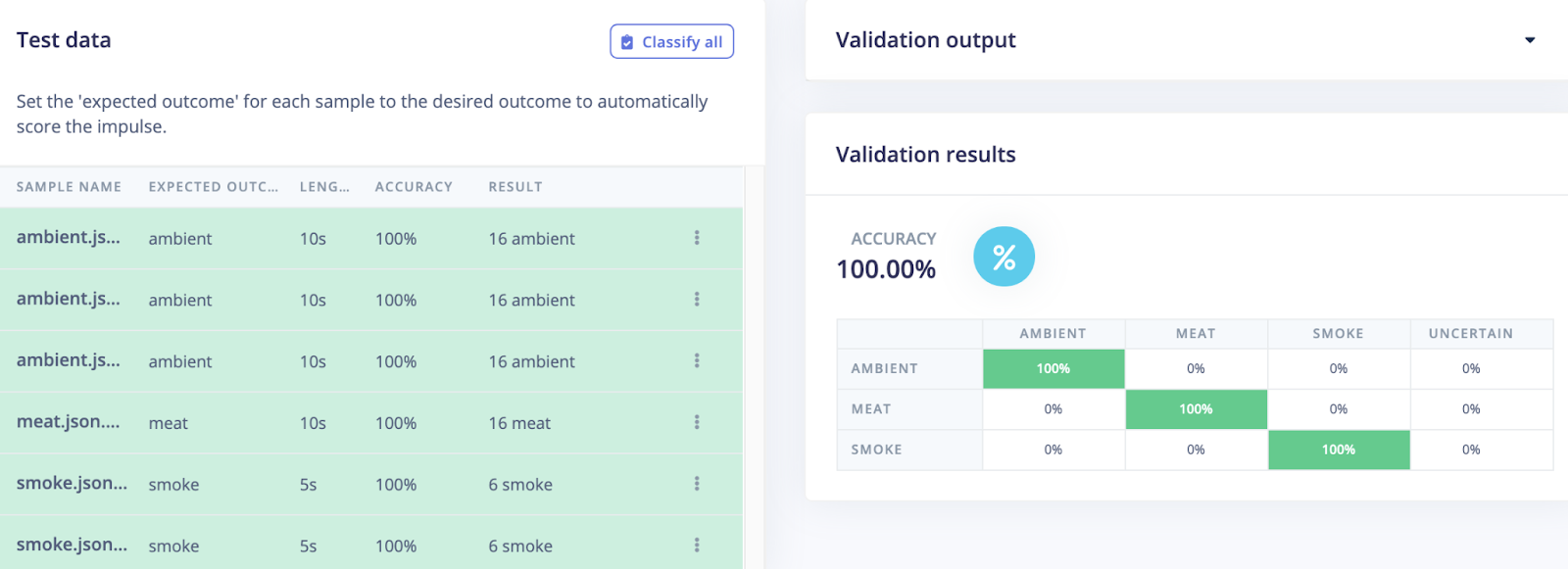
This is a simple example of how machine learning can be used to distinguish between smoke, nuisance smoke and no smoke conditions. However, as more data is added for the different classes, the algorithm can even be improved further. For example, expanding the “meat” class and gathering more data points for nuisance smoke would only increase the algorithm’s accuracy when it comes to differentiating between real and nuisance smoke.
With machine learning and sensor fusion, improving smoke detector performance has never been easier. Even with a very small dataset, we’ve demonstrated that it is possible to differentiate true smoke from cooking smoke.
If you are interested in trying it out yourself, this project is available publicly here.