
Backdrop
Ever since the invention of microcontrollers and microprocessors in the early 1970s, the compute aspect of embedded systems has evolved dramatically. In the last 50 years, not only has compute capability been constantly improving – as predicted by Gordon Moore – but it also become more affordable over time. These capabilities have evolved to cater to differing applications from cloud compute to true endpoint edge compute. At the so-called ‘edge,’ the transformation of almost every ‘thing’ around us to ‘Internet of Things,’ or fondly referred to as ‘IoT,’ has been happening right in front of our eyes at a rampant pace. Along with the compute revolution, the software world has been evolving dramatically as well. Staggering advancements in machine learning technology that started in the cloud have been proliferating to the edge since quite recently.
Jim Turley, senior editor of Microprocessor report, famously quoted way back in 1999 that ‘About zero percent of the world’s microprocessors are used in computers.’ He was referring to the fact that even back then, despite rapid adoption of laptops and desktop computers, the vast majority of microprocessors were used in other embedded systems like cars, medical devices, household appliances, consumer electronics and the like. 22 years later, in 2021, almost all devices around us have one or more microprocessors in them, incorporate one or more sensors, and they most probably also have some means of connecting to the cloud backend. John Hennessy of Stanford University made some keen statements about the convergence of three key changes:
- Technological changes: End of Dennard scaling and slowdown of Moore’s law.
- Architectural changes: End of uniprocessor era and end of multicore era.
- Application focus shifts: Ultra-scale cloud compute and IoT with key constraints; ML changing everything!
Effectively, compute challenges are gravitating towards the two extremes: ‘The cloud’ and ‘the edge.’ Let us take a look at what exactly is happening at the latter!
Computational hierarchy
While the early years of embedded compute saw just general-purpose MPU compute capability, with the advancement of math-intensive applications like music, video, gaming, etc., digital signal processors (DSPs), graphical processing units (GPUs), and very recently, neural processing units (NPUs) have become commonplace in modern silicon architectures used both in the cloud and in embedded systems used at the edge.
Each of these compute engines were used for specific purposes in most of the embedded systems. MPU was used primarily for running control logic, DSP and GPU engines were used exclusively for math intensive algorithms, and the neural network accelerators were used for running ML inference models.
What goes around, comes around
Two distinct trends are emerging concurrently:
- Silicon innovations where you have representations from three key compute engines: general purpose, math intensive, and neural (network) intensive compute engines.
- Software innovations by the name of tinyML, AutoML, and MLOps are improving the value proposition of all these three compute engines.
We are witnessing some of the early benefits of the collective hardware-centric and software-centric innovations both in ‘the cloud’ and at ‘the edge.’
Innovations around MPUs and DSPs have been incremental in recent years, but innovations in NPU have gone from 0 to 100 mph in a very short period of time – primarily driven by AI/ML computational demands. Better compute performance (speed) with lower power consumption has been one of the common themes behind most of these innovations. Both higher speed and lower power are of the essence for AI/ML adoption to continue. While ‘the cloud’ will continue to perform inferences for several use cases, edge compute innovations are making many inferences to happen right at ‘the edge’ where the data required for these ML models originates.
Instead of using one general-purpose compute engine with a specific instruction set architecture (ISA), the silicon strategy of recent years is to go with domain specific architecture (DSA).
Innovations like digital or analog in-memory compute and spiking neural networks used in neuromorphic compute for both ML model training and ML inferencing are no longer confined to concepts and simulations. Some of these bleeding-edge compute solutions are shipping in volume.
Why is this possible now? Fewer bits! Without sacrificing much on the ML model performance front, the number of bits required for the weights used in ML models is quite small – in the low single digits, while the number of bits/bytes/words required for most other compute types have been constantly trending north to accomplish ever increasing performance metrics.
ML models in general require fewer bits for each of the neural weights that form the neural network. TinyML models, because of some amazing advancements, utilizes a very compact footprint both in terms of program and data memory. Making ML inferencing a reality in highly resource constrained embedded systems. TinyML/AutoML is effectively extending lives, computational lives, of all types of compute engines.
One key reason for this is that the biggest compute bottlenecks for Deep Learning ML models are not matrix multiplies; rather, features like normalization, search, and sort create complex computational bottlenecks.
Even though all compute engines are beneficiaries, the biggest beneficiary is the MCU. Why so? A significant percentage of the embedded processors that have been shipped till date only have an MCU in them. More sophisticated processors intended for mobile phones and other high-end consumer electronics have DSPs and/or GPUs integrated in them. Only a tiny fraction of the embedded processors shipped have integrated NPUs in them, although that number is growing rapidly. These concepts are shown in the following figures.
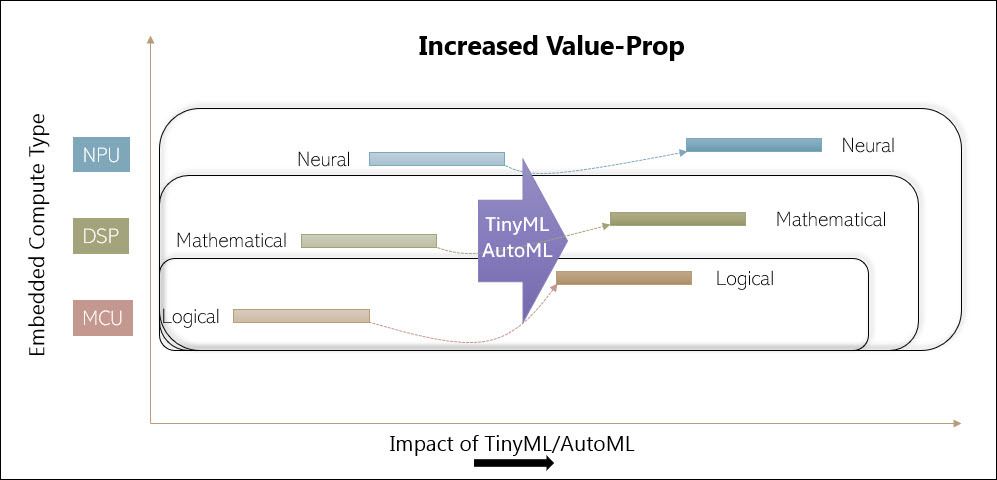
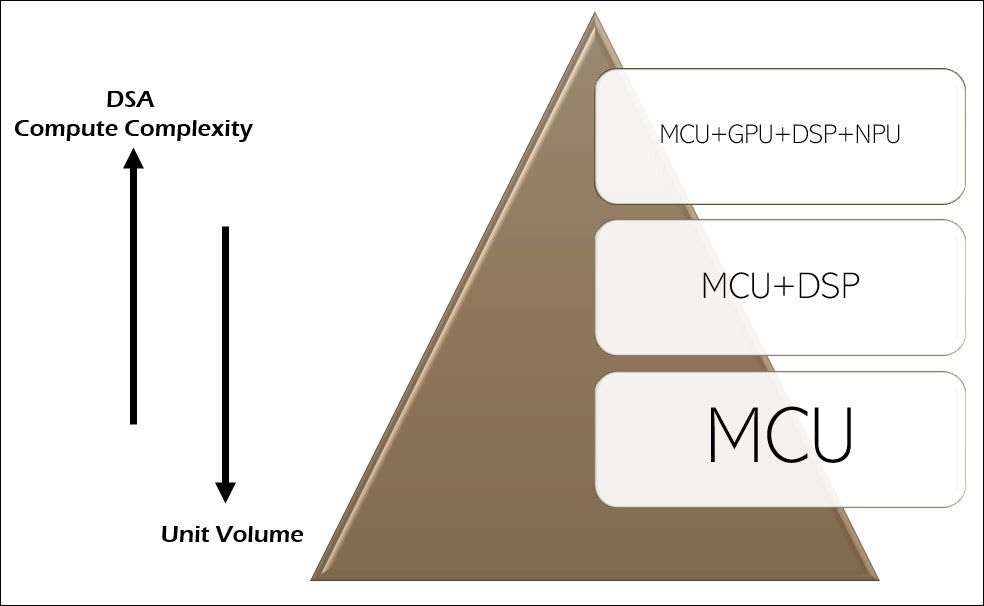
Upvalue the ‘brown field’
- Hardware innovations: Even basic MCUs are powerful enough to run these algorithms.
- Software innovations: The tooling for running machine learning on these devices, and optimizing machine learning models for low end compute, has become mature.
- Architectural innovations: Efficient deep learning model architectures have been developed that can make the most of limited compute and memory budgets.
At the edge, modern software concepts around tinyML and AutoML are helping organizations extract more value from what they already have. Zach Shelby, CEO and co-founder of Edge Impulse, calls this the “brown field” opportunity.
Here’s an interesting note from Arm, which is a licensee of one of the world’s most popular microprocessor architectures to chip-manufacturers worldwide:
In the fourth quarter of 2020:
- Arm silicon partners shipped a record 6.7 billion Arm-based chips, the third record quarter for unit shipments in the past two years.
- Arm saw growing demand for embedded intelligence in endpoint devices as demonstrated by the record 4.2 billion Cortex-M processors shipped.
To date, Arm partners have shipped more than 160 billion Arm-based chips, and an average of more than 22 billion over the past three years.

Someone did the math and calculated that about 842 chips featuring Arm’s IP gets shipped every single second! That’s just Arm! x86, ARC, Power, RISC-V and MIPS are the other popular CPU ISAs. These non-ARM ISA architectures collectively do not exceed the number of Arm-based chips shipped.
So, in effect, the enormity of what’s happening out there – the growth in the number of both Arm- and non-Arm-based chips is apparent. This growth curve would keep trending with the same pace, or even faster, if not for what has been happening recently in the real world.
Weather forecast?
Digital transformation that encompasses rapid adoption of work-from-home and remote work concepts, proliferation of AI/ML everywhere from the cloud to the edge, smartification of ‘everything’ from cities, to factories, to enterprises, to cars, to homes, to ramp-up of 5G deployments etc., are fueling the demand for microprocessors of all kinds.
In addition to all these demand-side variables, a few additional logistical factors have taken shape recently:
- Starting with TSMC, foundries are in the process of increasing chip prices.
- Cost of freight all over the world has been increasing exponentially and is expected to stay high due to supply chain disruptions – some of which are permanent.
- Demand for ‘legacy’ (200mm) wafers is higher than it is for ‘next-gen’ (300mm) wafers because of increased demand for more mature tech
- Rapid consolidation in the silicon space: Acquisition of Dialog Semi by Renesas; Acquisition of Conexant and DSP Group by Synaptics.
- Rampant VC funding into AI/ML silicon space:
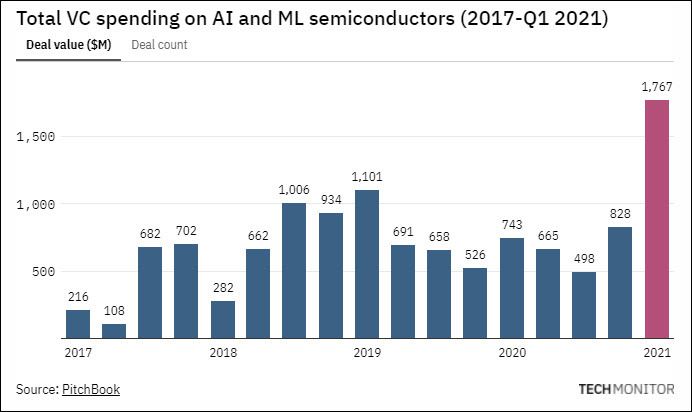
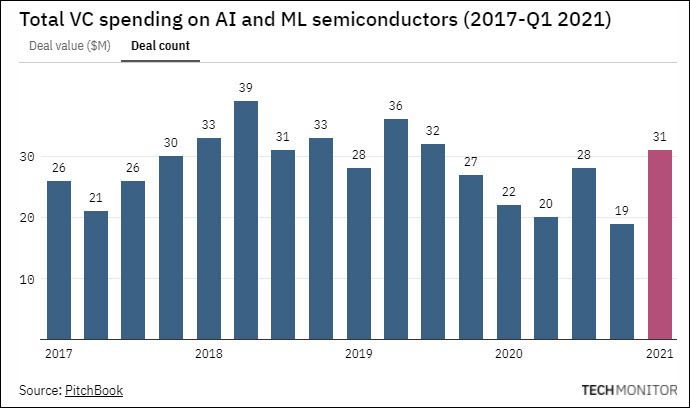
In effect, the cost of gadgets that use these chips are bound to increase. When customers pay more, they expect more. Device manufacturers cannot keep doing the same old and expect customers to pay more, and competition doesn’t stand still either. So, a perfect storm of sorts is brewing for a significant number of device manufacturers. They need to either… innovate or die!
Edge AI to the rescue
TinyML is synonymous with edge AI. Groundbreaking software innovations in tinyML, AutoML, and machine learning operations (MLOps) platforms like those offered by Edge Impulse, allow device manufacturers to:
- Effectively uncover unrealized potential from most of their ‘brown field’ devices with legacy microprocessor ISAs, as well as
- Manage the ML lifecycle and requirements for more advanced next-gen DSA-based devices.
An MLOps platform is a cloud-based collaborative development environment that handles everything from data pipelines to model prep, motel testing, model deployment, DevOps, cataloging, and governance.
Edge Impulse is the leading MLOps platform today enabling the design and development of embedded machine learning algorithms. With its low to no code visual platform, it has democratized the previously fragmented edge machine learning space to allow users who are unfamiliar with machine learning to train, test, deploy, and maintain embedded ML models.
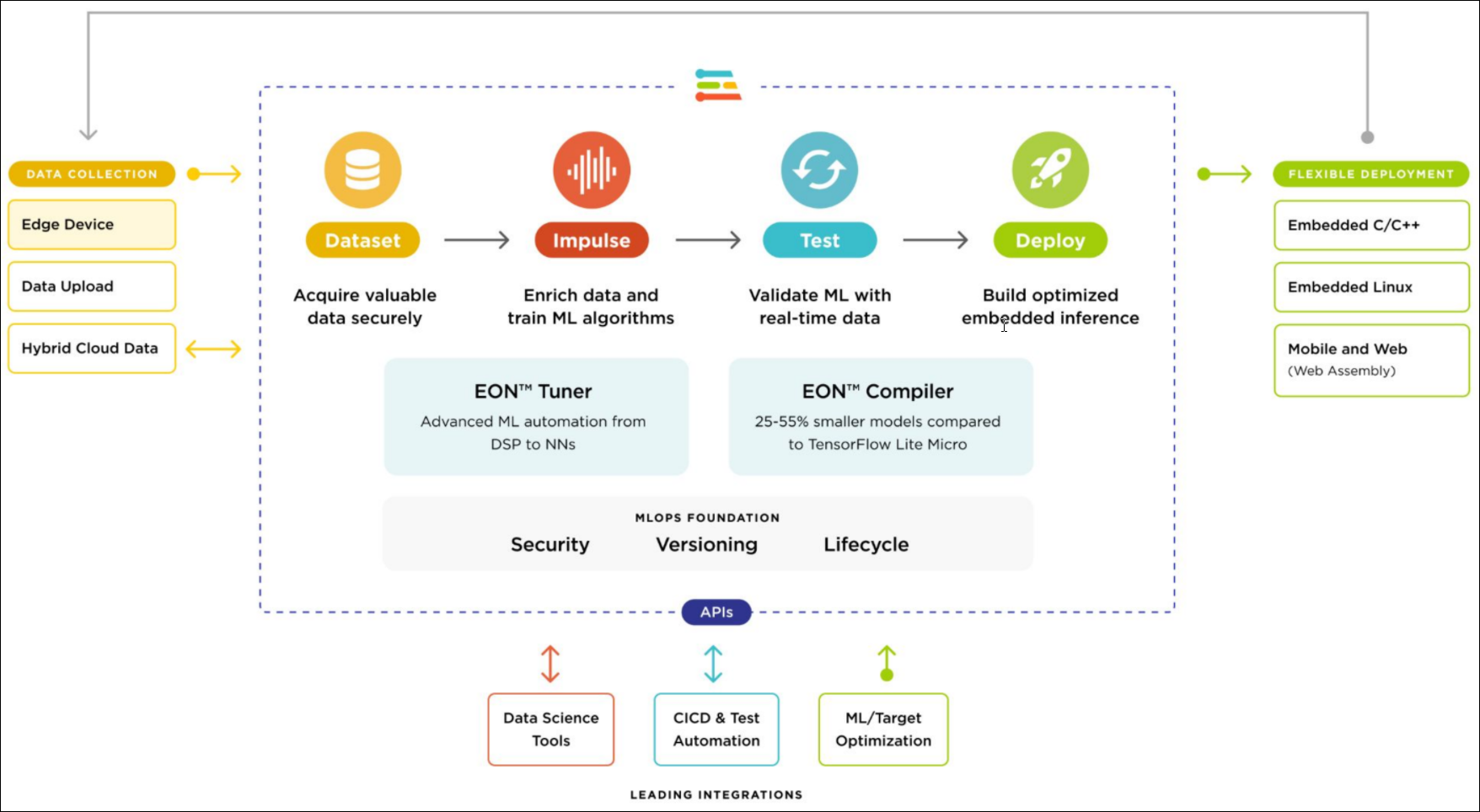
Edge Impulse is leading the way in creating production-grade software algorithms that are shipped to new devices and old alike. This enables product manufacturers to bring intelligence to previous generations of devices via a firmware upgrade or over-the-air (OTA) update.
Conclusion
What started as a transformation of ‘things’ to the ‘Internet of Things’ has now transitioned to addition of intelligence onto these endpoint devices. Edge compute and concepts like tinyML are fueling that evolution. In addition to powering embedded systems using modern silicon solutions, Edge Impulse’s platform aids with the development and deployment of ML models big in performance but highly compact in size that are ready to power billions of installed-bases of endpoint devices – the ‘brown field’ devices.
Are you ready to add more value to your brown field devices? Feel free to reach out to us at Edge Impulse so that we can help figure out how to infuse a breath of new life to all your embedded devices: both new and legacy embedded systems.