
In the rapidly evolving field of artificial intelligence (AI), data is the lifeblood of innovation. It is what trains machine learning models, allowing them to learn patterns and make predictions. The quality, quantity, and diversity of this data directly determine an AI system's performance and accuracy. Consequently, as a general rule, no matter how much data they have, AI researchers and developers could always use just a little bit more.
Unfortunately, the problem of getting access to adequate datasets is only growing worse as models grow larger and become more sophisticated. Acquiring, labeling, and cleaning high-quality data to fuel progress is often prohibitively expensive, time-consuming, or logistically complex, creating a bottleneck that slows down the deployment and refinement of next-generation AI systems.
Cosmos: NVIDIA’s reality generator
It is becoming increasingly clear that traditional data collection methods alone cannot sustain the current pace of AI development. Fortunately, as Eivind Holt recently explained, help is on the horizon. Holt took a deep dive into NVIDIA’s Cosmos Predict, which is a branch of their Cosmos World Foundation Models (WFMs) ecosystem. Using Cosmos Predict, an endless stream of still images or videos can be generated by simply supplying a text-based description of what is needed. Best of all, using these synthetic datasets to train models with the Edge Impulse platform is a snap.

In his exploration, Holt demonstrated a workflow for developers who need thousands or millions of customized samples without the logistical headache traditionally associated with dataset creation. Cosmos Predict’s role within NVIDIA’s broader Cosmos WFM suite is to provide a generative engine capable of producing richly detailed visual data on demand. Whether researchers need video footage for a self-driving vehicle or still images for a warehouse robot, the system can oblige with precision that is often surprising.
Holt focused on the 2B and 14B parameter variants of the Cosmos-Predict2 models, which are pre-trained on curated robotics and driving data to make them physics-aware. Unlike general-purpose image generators that might hallucinate impossible geometries, Cosmos Predict creates scenes that align closely with the rigid constraints of the physical world. This is an especially important consideration when embedding AI into physical systems.
Getting a boost from LLMs
However, generating a single image is only the start. To train a robust model, one needs variety. Even with Cosmos, generating enough variety could be a tall order. To automate the process, Holt described how Large Language Models (LLMs) can be used to augment the image generation process. By feeding a base requirement into an LLM (for example, "a factory line with soda cans") a developer can request hundreds of nuanced variations. The LLM generates a JSON file containing diverse prompts with different lighting conditions, varying conveyor belt colors, or changes in camera angles.

This file is then fed into Cosmos Predict, which works to render each of these scenarios. In Holt's testing utilizing a local NVIDIA GeForce RTX 5090 GPU, the system churned out over 6,000 images in a 30-hour session. While the hardware requirements are steep — the 2B Text2Image model alone requires more than 26GB of VRAM — the result is worth the price. This produced a massive, domain-specific dataset without a single real-world photograph, and with compute time as the only cost.
Automating annotation
Without annotation, these images are essentially useless for supervised learning. Traditionally, turning these synthetic images into training data would require humans to draw bounding boxes around every soda can, forklift, or other object of interest. This task would negate the speed advantages of synthetic generation. So to automate the process, Holt’s workflow utilizes Grounded SAM 2, an open-vocabulary object detection pipeline. By simply providing a text prompt like "can. person. forklift.", the model scans the synthetic images and automatically generates segmentation masks and bounding boxes.
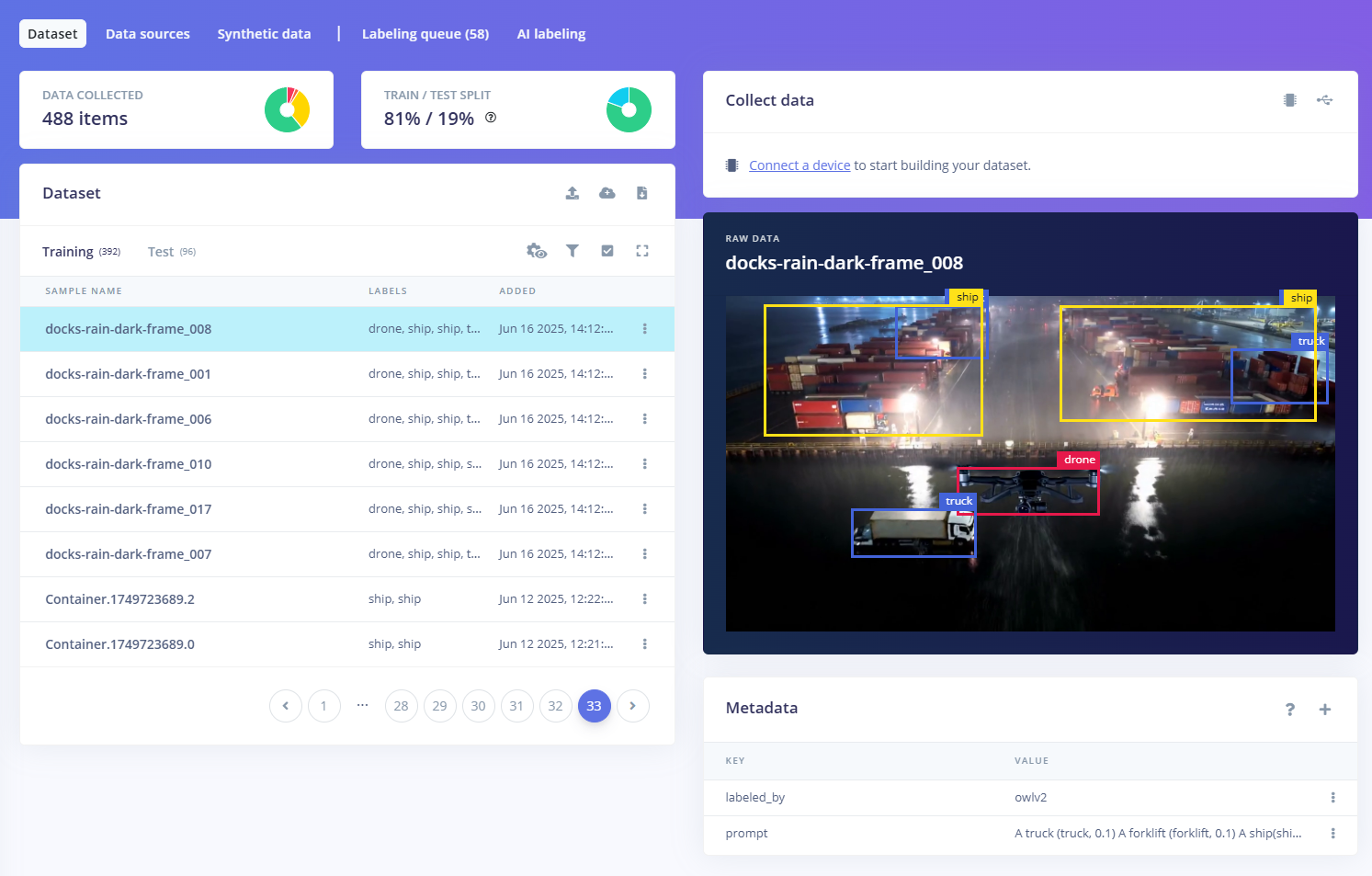
With fully annotated images in hand, Holt could get started on the fun part: building and deploying a machine learning model with Edge Impulse. The Edge Impulse platform excels in turning real or synthetic raw datasets into deployable models optimized for devices ranging from microcontrollers to edge GPUs. But its value becomes even more apparent when combined with a synthetic data pipeline like Cosmos Predict. Rather than users spending days preparing a dataset before uploading, Edge Impulse can ingest tens of thousands of annotated samples at once, streamlining a process that once required entire teams of data technicians.
Speeding up the AI development cycle
Holt wrote a short script to convert the image annotations into the Pascal VOC XML format. After that, he imported everything directly into an Edge Impulse project. The platform immediately recognized bounding boxes and object classes, displaying them in the Data Explorer tool. This tight integration allows developers to rapidly iterate on factors such as dataset size, class balance, lighting variation, and scene composition as needed.
Once the dataset was loaded, Holt moved on to designing an object detection pipeline using Edge Impulse Studio’s built-in tools. The platform has a large selection of model architectures available that are tuned for real-time inference on edge hardware. With just a few clicks, he trained a detector capable of recognizing soda cans and other factory objects across varied scenarios. The consistency of the synthetic images contributed to noticeably stable training behavior: the model converged quickly and delivered excellent validation metrics, despite never seeing a real-world photograph.
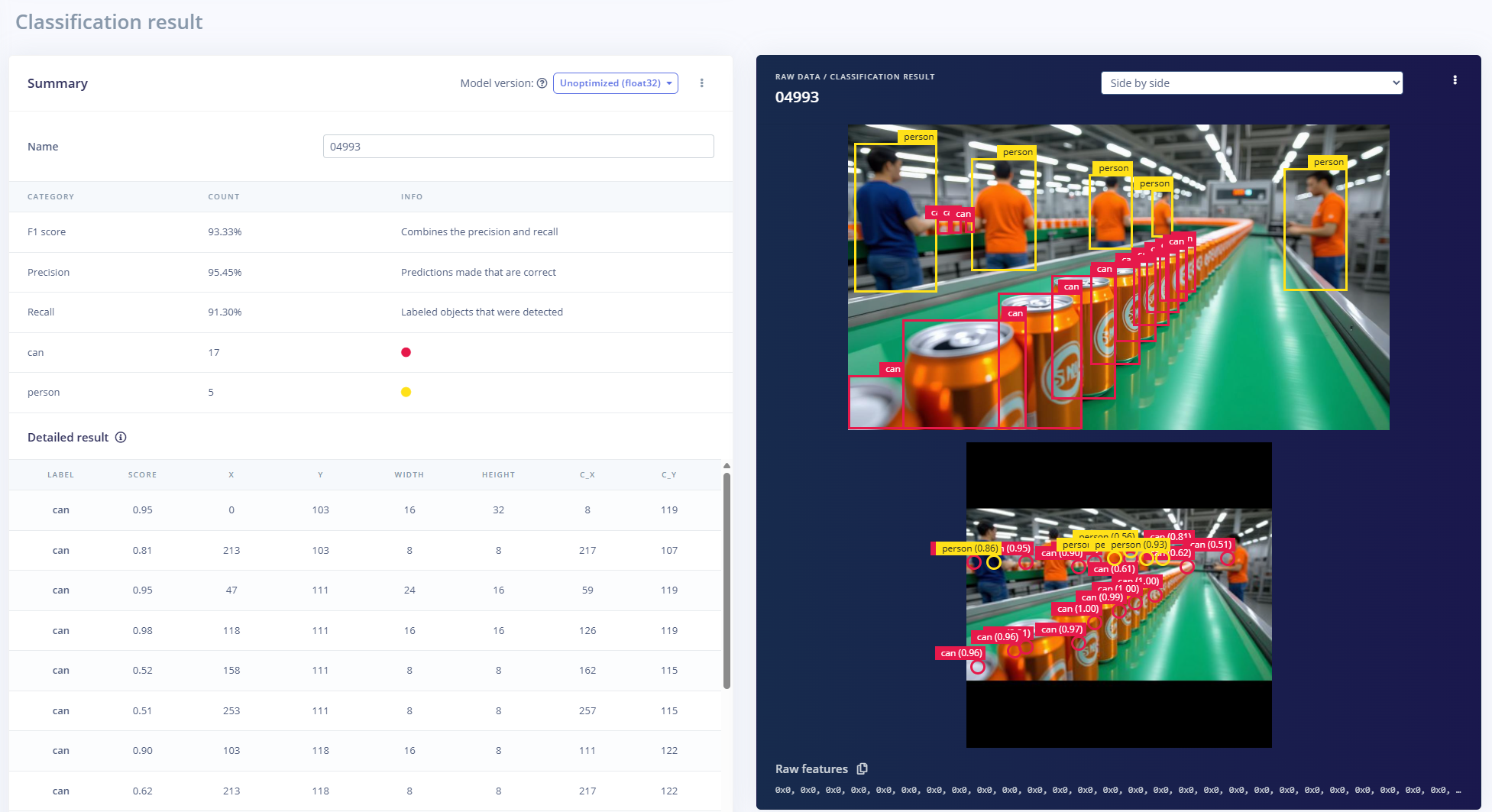
Once Holt had a satisfactory model, Edge Impulse allowed him to export it as a TensorRT library, enabling easy deployment to NVIDIA GPUs or Jetson devices. This flexibility is important in industrial robotics or factory automation, where each deployment environment may dictate unique constraints. Using synthetic data from Cosmos Predict, a developer can train and validate a model in Edge Impulse Studio, then ship it to an embedded GPU system without rewriting code.
Custom-tailored AI on demand
This workflow — Cosmos Predict for data generation, Grounded SAM 2 for automated labeling, and Edge Impulse for training and deployment — makes professional-grade AI more accessible and practical than ever. Instead of slow, incremental dataset collection cycles, engineers can spin up domain-specific datasets tailored to their exact needs. Want a warehouse robot capable of detecting safety hazards under dozens of lighting conditions? Generate them. Need a household robot to identify cluttered objects on different floor textures? Describe them. The boundaries of what can be taught no longer depend on the messy realities of physical data capture.
To find out how NVIDIA Cosmos and Edge Impulse can accelerate your own AI development lifecycles, check out Holt’s very detailed analysis. Once you are ready to move forward, you’ll also find all the information you need to get your first prototype up and running.