
There are huge benefits to running deep learning models “at the edge”, on hardware that is connected directly to sensors.
Using deep learning to analyze data where it comes from—instead of sending it to remote servers—allows products to preserve privacy, avoid network latency or bandwidth requirements, and even save power since processor cycles are cheaper than radio comms.
This unlocks a whole tree of new technology applications. Imagine a $1 chip that outputs a binary yes/no depending on whether a person is in the frame of its camera or smart sensors that monitor animal health in remote farms and report back problems via low-power satellite radio. We can make use of our world’s data without having to capture and log it all.
There’s just one problem: edge devices generally have far less computational power than web servers. For example, the STM32L4 series of MCUs (microcontroller units) is typical of the embedded single-chip computers that power many household and industrial objects. The snappily-named STM32L475 has 128 KB of RAM, up to 1 MB of flash memory (which is used for storing programs), and runs at 80 MHz. It can draw as little as 195 nanoamps (1.95e-7 amps) of current while doing useful work.

This may be faster than the 486 I learned to code on in the 90s, but the low clock rate and memory make it hard to run even the smallest models optimized for mobile phones. A MobileNet v1 image classification model that gets 70% top-1 accuracy (meaning during testing it can match 70% of images with their corresponding classes) is 16.9 MB, and using it to make one prediction requires 418 million multiply-accumulate operations. Based on some back of the envelope calculation, this would take approximately 12 minutes on our STM32L475!
While this would be okay for some applications—perhaps we’re monitoring a glacier, a tree, or a particularly ancient tortoise—12 minutes of latency is generally not ideal. The faster we can make each prediction, the less energy our device will use, since we can put the processor to sleep when it is not in use.
To make our models work with edge devices, we need to do two things: make them smaller, so they fit in limited memory and make them computationally cheaper to run. There are many ways we can do this, so let’s start to explore.
Smaller, simpler models
The MobileNet v1 model we’ve been discussing has the following properties:
- It takes a 192x192 color bitmap as input
- It can identify 1000 different types of objects
- It makes the correct prediction 70% of the time
- Its internal state is represented by 32-bit floating-point numbers
- It is 16.9 MB in size
This is a highly capable model—it can do things that 10 years ago would have been considered magical. But this capability comes at a cost. All of the model’s knowledge about 1000 different types of objects is encoded in its internal weights and biases, which are what take up most of that 16.9 MB. Each prediction requires a calculation that involves all of these numbers, which is why they take so long to perform.

For most applications, it’s not necessary to recognize 1000 different types of objects. For example, imagine we’re building a smart sensor that counts cats. Every day, it sends a radio broadcast encoding the number of times that a cat walked past. In this case, the model would only need to successfully classify two things: cats, and things that are not cats.
As you might expect, there’s far less information required to discriminate between “cats” and “not-cats” than between 1000 different classes. This means that if we design a smaller version of the model architecture, with fewer layers of neurons and fewer neurons per layer, we can probably reduce its size by a large amount and still keep the same degree of accuracy.
This is almost definitely the best way to shrink your model size: reduce its scope. The easier the problem the model has to solve, the less internal state it will need, and the less memory and multiply-accumulates it will require.
We can apply the same line of thinking to the model’s accuracy. Do we need 70% accuracy, or can we get away with less? Lower accuracy requires less information, so if we are okay with 60% accuracy instead of 70%, we can probably make the model smaller.
Another way to shrink our model is by reducing the amount of data we feed in. It’s possible we can still get acceptable accuracy with a 96x96 input, which has nearly half the number of pixels of a 128x128. It might be the case that color isn’t necessary for our application, in which case we could replace our three color channels with a single set of values, reducing the input size by two thirds.
Shrinking your model’s scope is an iterative process. It’s all about finding the right balance of capabilities, accuracy, and model size. You can play with these tradeoffs during the research stage of your project until you’ve found the model architecture that works best for you—or until you’ve decided that this problem is not solvable with a tiny model.
Once you have a model with acceptable performance, you can reduce its size even further with some clever optimizations.
Integers, not floating points
By default, most deep learning frameworks (like TensorFlow and PyTorch) use 32-bit floating-point numbers to store their models’ internal state. It turns out that the graphic processing units in modern desktop and server computers are extremely good at performing matrix operations with floating-point numbers, which makes training deep learning networks a lot faster—so it makes sense for models to have floating-point weights.
A 32-bit single precision floating point number can represent a huge range of values, but due to the way the algorithms work, the numbers in a deep learning model generally hover around 0 in the range between -1 and 1. This means that most of the capacity of these 32-bit numbers goes unused. In theory, it should be possible to squeeze the same distribution of values into a much smaller representation—for example, a signed 8-bit integer.
In the following visualization, courtesy of the TensorFlow blog, you can see this in action. The histogram at the bottom shows how the weight values in a network are clustered around 0, and the rest of the range is empty. The histogram at the top shows how the values can be mapped onto the much smaller range of an int8.
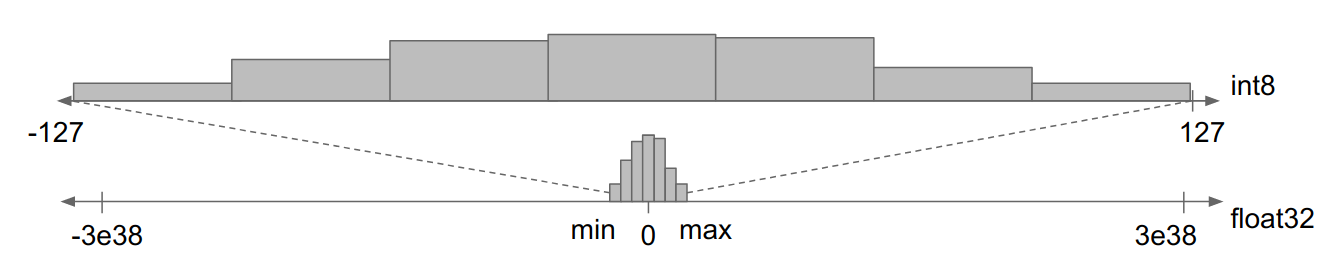
Reducing the precision of a model’s internal state with this technique is known as model quantization. In theory, performing model quantization could result in a loss of accuracy, since we’re giving up so much precision in the representation of numbers. In practice, deep learning algorithms are resilient against these types of changes, and accuracy loss is generally very low.
By using 8-bit instead of 32-bit numbers, we can shrink down our model so that it is one-fourth of its original size and works almost as well as the original. The trade-off is that we’ll need to write special 8-bit integer implementations of the mathematical operations that make up the model. Fortunately, frameworks like TensorFlow Lite for Microcontrollers already have these implementations written, so we’re good to go!
Quantization is a no-brainer for most edge machine learning projects. Most models lose a little accuracy in the process, but since the resulting model is so much smaller, you can generally make up for the loss by making the model slightly larger to begin with.
There’s another big win from using quantized models. Many processors have floating-point units (FPUs), which make floating-point maths run faster. However, there are a lot of microcontrollers that aren’t equipped with FPUs. They can still do floating-point computations, but they do so extremely slowly. By converting into an integer representation, models will run a lot faster on these types of devices.
It’s possible to go beyond 8-bit precision: there is research happening around 4-bit, 2-bit, or even binarized (1-bit) deep neural networks. However, most of the tools available right now are designed to work with 8-bit quantization, so it’s the most common type.
Hardware-specific optimizations
In the world of big, powerful computers, it’s rare for most developers to think about low-level computation. We spend most of our time dealing with abstractions that hide complexity and reduce the mental overhead of writing code. We’re usually happy to pay the tradeoff, which is that we’re not squeezing out every last drop of performance from the hardware we are using. It’s okay because modern processors are cheap and powerful.
Working with tiny embedded microcontrollers, things are completely different. When you have a double-digit clock rate and a few kilobytes of RAM, it’s extremely important to make the most out of limited resources. It’s common for embedded developers to use every trick they can to get the most out of their hardware.
Complicating matters further, there are thousands of different types of microcontrollers, each with different quirks, features, and characteristics. There’s no guarantee that what performs well on one device will be acceptable on another. For example, a neural network with 32-bit floating-point weights might run fine on a STM32L475 MCU, which has a floating point unit—but perform terribly on an STM32L1 Series, which doesn’t.
It follows, then, that to run a deep learning model as fast as possible will involve optimizations that take the hardware into account. On a given device, there may be faster or slower ways to do the same work. In fact, some more recent microcontrollers even provide special features specifically for accelerating deep learning computations—but they usually need to be accessed in a certain way.
Luckily, hardware vendors do their best to help. For example, when working with MCUs based on Arm’s Cortex-M series of microcontroller processor designs, developers can use the CMSIS-NN library. This provides code written by Arm that implements most of the important deep learning mathematical operations, such as matrix multiplications, in the most efficient way possible for their particular processors.
To make sure your models run as quickly as possible, it’s important to factor this in. Are you targeting a platform that has optimizations available? If so, you can potentially run a larger, more accurate model and still see good performance. If not, you may have to compromise on model accuracy in order to get the performance you need. Testing your model on the target hardware is a vital part of the development process.
The good news is that many hardware companies are working closely with the makers of deep learning frameworks to make sure that their processors are well supported. For example, TensorFlow Lite for Microcontrollers currently provides optimizations for some Arm, Cadence and Synopsys processors, and the list is always growing.
There are now dozens of companies creating microcontrollers designed specifically for running deep learning code, so you can expect hardware choice to become an increasingly important part of designing an embedded system that uses deep learning.
Trying it yourself
There’s a lot to think about here, and since deep learning on tiny devices (a.k.a. “TinyML”) is still an evolving field, the state of the art is still changing fast. There are a lot of technologies in the pipeline that promise to deliver smaller models, and faster performance, and greater ease of use for developers, but it can be difficult to know where to start.
When you train a model in Edge Impulse, we automatically perform quantization, reducing its memory footprint to one-fourth of its original size. We then estimate its performance and memory requirements based on its architecture. These two screenshots show statistics for the same model, with and without quantization applied:
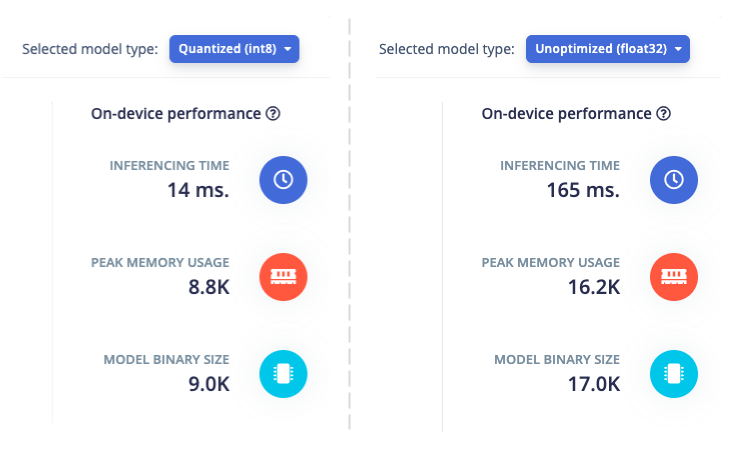
As you can see, quantization has a huge impact on this model’s performance. The quantized model is more than 10 times faster and uses around half the memory of the unoptimized model when running on the target architecture.
If you’d like to explore model optimization yourself, you don’t even need any hardware to get started—Edge Impulse supports mobile web browsers using WebAssembly, so you can capture data and deploy models to your mobile phone for testing.
Try these tutorials and pre-built datasets to train a model in less than five minutes:
If you give Edge Impulse a try, or if you have any questions, we’d love to hear from you. Join us on our forum and let us know what you’re planning to build!
- Daniel Situnayake
Dan is the Founding TinyML Engineer at Edge Impulse. He’s the co-author of O’Reilly’s TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers, which helps organize international TinyML meetups, and was previously on the TensorFlow Lite team at Google.
__
Cover photo by Zdeněk Macháček.