
Signal processing is key to embedded machine learning. It cleans up sensor data, can highlight interesting signals, and drastically reduces the number of features that you pass into a machine learning algorithm - making models run faster and more predictable. To build better audio models, especially for non-voice audio (elephants trumpeting, glass breaking, detecting whether you’re in a factory or outside), we’ve updated the MFE and spectrogram signal processing blocks in Edge Impulse to feature better accuracy, improved tweakability, and yet fast enough to run on any typical microcontroller.
A typical signal processing step for audio is to convert the raw audio signal into a spectrogram, and then feed the spectrogram into a neural network. This has the benefit of reducing the data stream from 16,000 raw features (when sampling at 16KHz) to under 1,000, lets you remove noise, or highlight frequencies that the human ear is tuned for. This makes it much easier for the neural network to efficiently classify the audio.
More detail, 33% less RAM
In Edge Impulse we have three different ways of generating these spectrograms. There is MFCC (for human speech), MFE (for non-voice audio, but still tuned to the human ear), and ordinary spectrograms (which contain no frequency normalization). In this release we’ve updated the MFE and spectrogram blocks to better normalize incoming and outgoing data, and have added a configurable noise floor, making it very easy to filter out background noise. Together these changes do a much better job at retaining the interesting information in a signal, and can have a drastic increase in accuracy of your models.
Here’s an example of an MFE spectrogram of an elephant trumpeting:
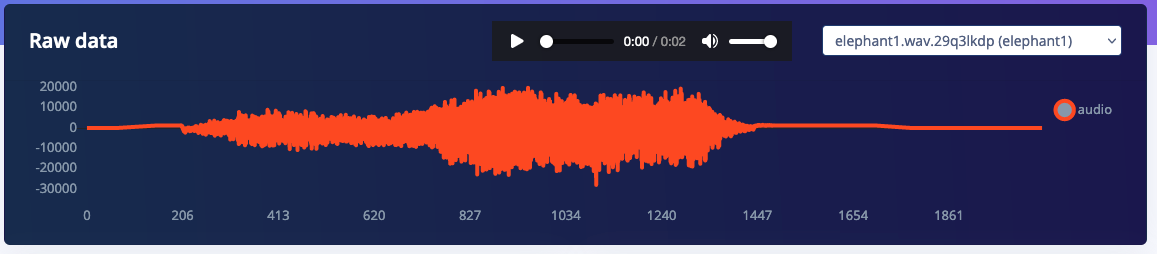
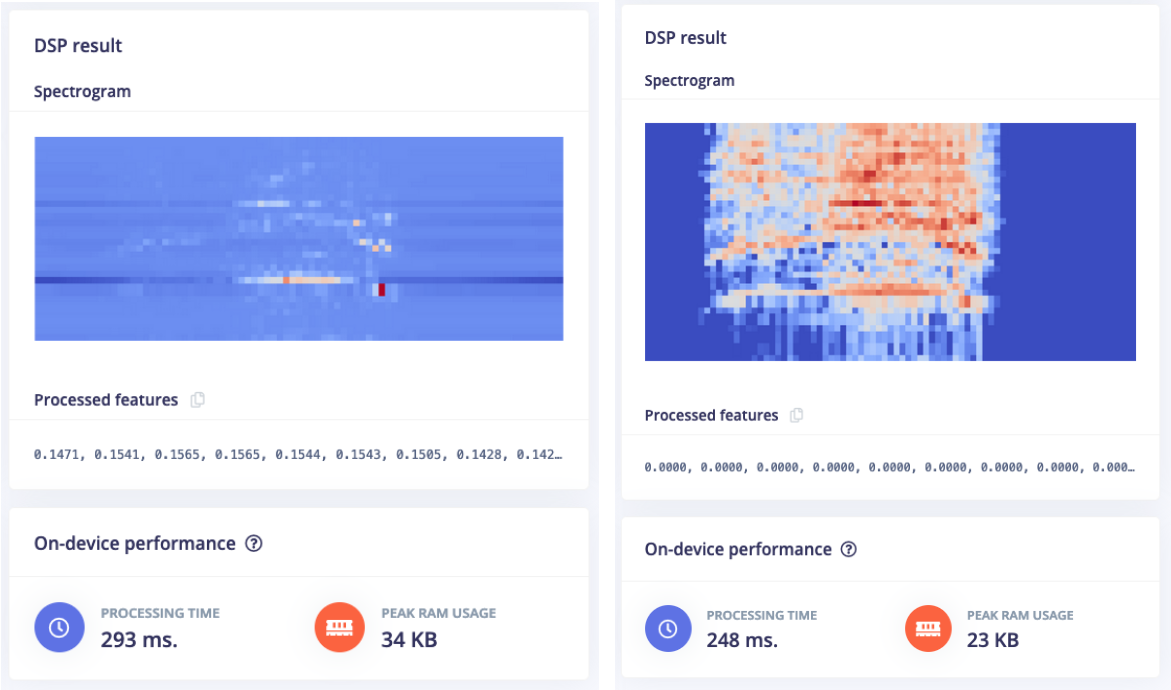
As you can see we don’t just have a lot more information in the resulting MFE spectrogram, but the updated block runs faster (processing time is to process 2 seconds of audio on a Cortex-M4F at 80MHz) and uses 33% less RAM.
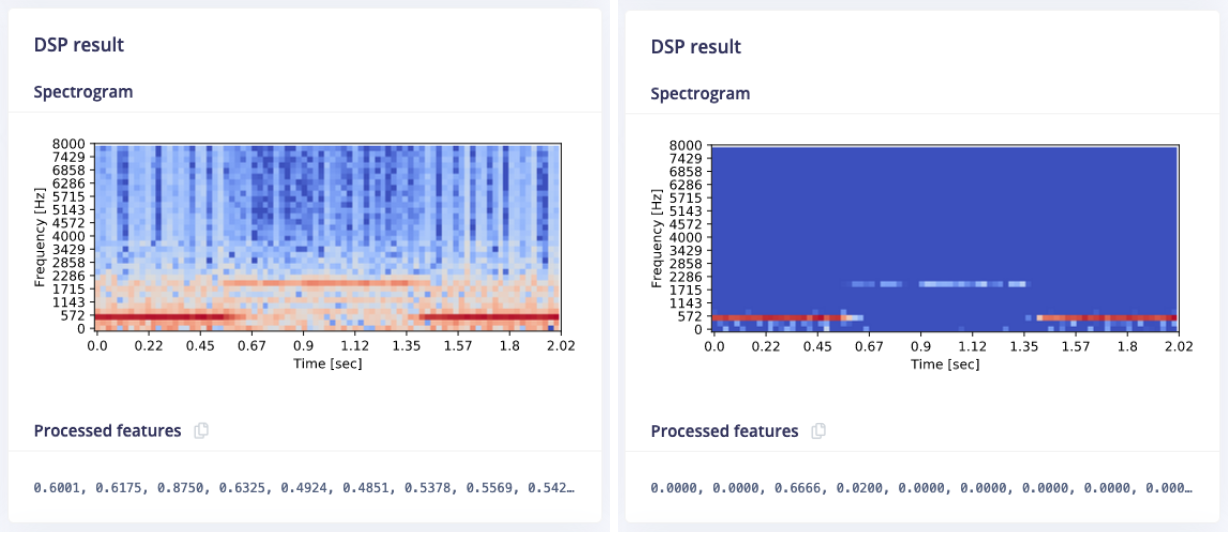
We see the same thing for normal spectrograms. Here’s an example of a police siren:
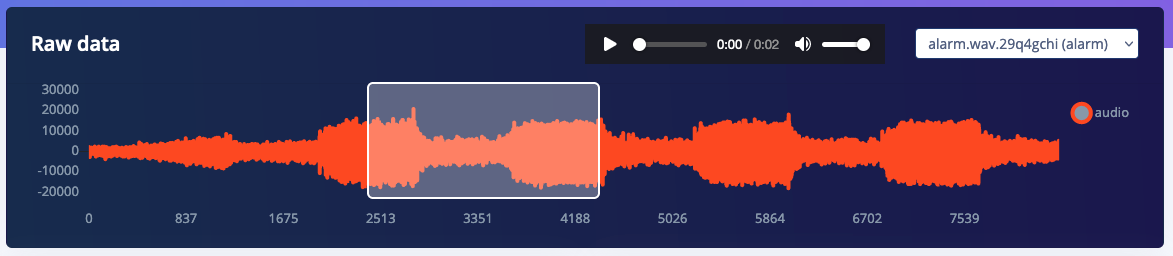
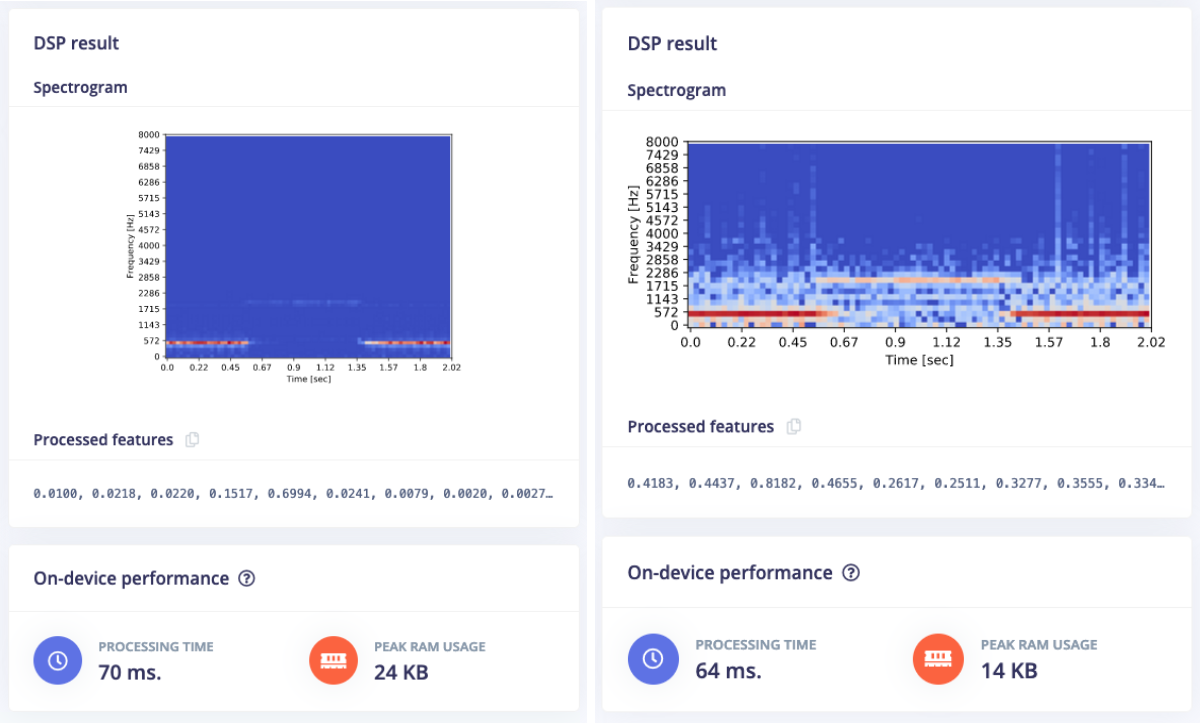
An additional benefit of the new blocks is that they have a configurable noise floor, making it easy to remove noise if you know that audio is loud enough. E.g. here’s the police siren with the noise floor at -52 Db and at -12 Db:
Increased accuracy, same performance
Together these changes can have a profound effect on your model accuracy. Training a bird sound classifier with the old MFE block and the new MFE block yields a 7% point increase in accuracy, an amazing feat that doesn’t require any additional processing power on the device. The new blocks are also a lot more resistant against quantization error.
If you’re using an MFCC block today on non-voice audio (as was used in the project above) you can also expect an increase in both accuracy and performance. The new MFE block is about 48% faster than the MFCC block (measured on Cortex-M4F), and also has higher accuracy than the MFCC block on many projects (e.g. ~7% point increase on this tutorial).
Getting started
Excited? It’s trivial to get started. Head to the Edge Impulse Studio, open an audio project, and on the Create Impulse screen add an MFE or spectrogram block. If you don’t have a project yet, see the recognize sound from audio tutorial to get started in a few minutes. If you already have an MFE or spectrogram block in your project you’ll need to delete and then re-add the block to get the new version (the ’noise floor’ setting is only visible for new blocks, if you need a visual cue).
Naturally these blocks are fully integrated in the Edge Impulse Inferencing SDK for both microcontrollers and Linux devices. This gives you optimal performance (with full hardware acceleration on many MCUs), with the ability to do realtime audio classification on even 40MHz microcontrollers. In addition we’ve done a lot of work in ensuring that continuous audio sampling works for all blocks, making sure you never miss an event, even on the smallest devices.
Questions? Remarks? Let us know on the forums! The source code of the new blocks is also available on GitHub (Python, C++) if you want to have a look.
Jan Jongboom is the CTO and cofounder of Edge Impulse. He loves things that respond to his voice.