
Today we shipped probably the biggest release since we launched Edge Impulse! We are very excited to announce that we rolled out a pair of incredible features: data sources and the data explorer. Together these two features enhance the way you collect your data, label, and explore your new data samples to create active learning pipelines.
When creating a supervised machine learning project, the most tedious job is to create a quality-labeled dataset.
The first iterations of your project won’t be as accurate as expected. This is normal, your model needs more data to perform better. But, this should not prevent you from getting started, on the contrary. What you need to achieve is to keep gathering new data over time to improve your model performances.
Indeed, once you have a few devices in the field, it is easy to grab some data samples, properly recognized or not, and, forward them directly to a cloud storage bucket or to your Edge Impulse project using the API.
Let’s take the example of a device in a factory that is used to recognize from the sound which process an industrial machine is executing such as drilling, sanding, engraving, or painting.
When running the inference on that device, if the confidence score is below a defined threshold, let’s say 60%, you can automate a process to automatically upload this data sample in an unknown cloud bucket folder to label it later and reuse it during the next iteration of your model training.
The same can be applied to some randomly selected samples with a confidence score higher than 75% and put them in the corresponding folder called drilling, sanding, engraving, or painting. You will see later how you can then infer from the folder name to automatically import that labeled sample into your dataset.
And to help you accomplish this entire loop, we recently integrated new features to ease your data ingestion from external cloud storage and to help you to understand these new data samples. The data explorer will also assist you in labeling your data. Awesome, right?
Understand your data samples with the data explorer
The data explorer is a visual tool to explore your dataset, find outliers or mislabeled data, and help label unlabeled data. The data explorer first tries to extract meaningful features from your data (through signal processing and neural network embeddings) and then uses a dimensionality reduction algorithm to map these features to a 2D space. This gives you a one-look overview of your complete dataset.
You have 3 options to choose from when generating the data explorer:
- Using a pre-trained model, available for images and keyword spotting
- Using the preprocessing blocks in your impulse
- Using your already-trained impulse

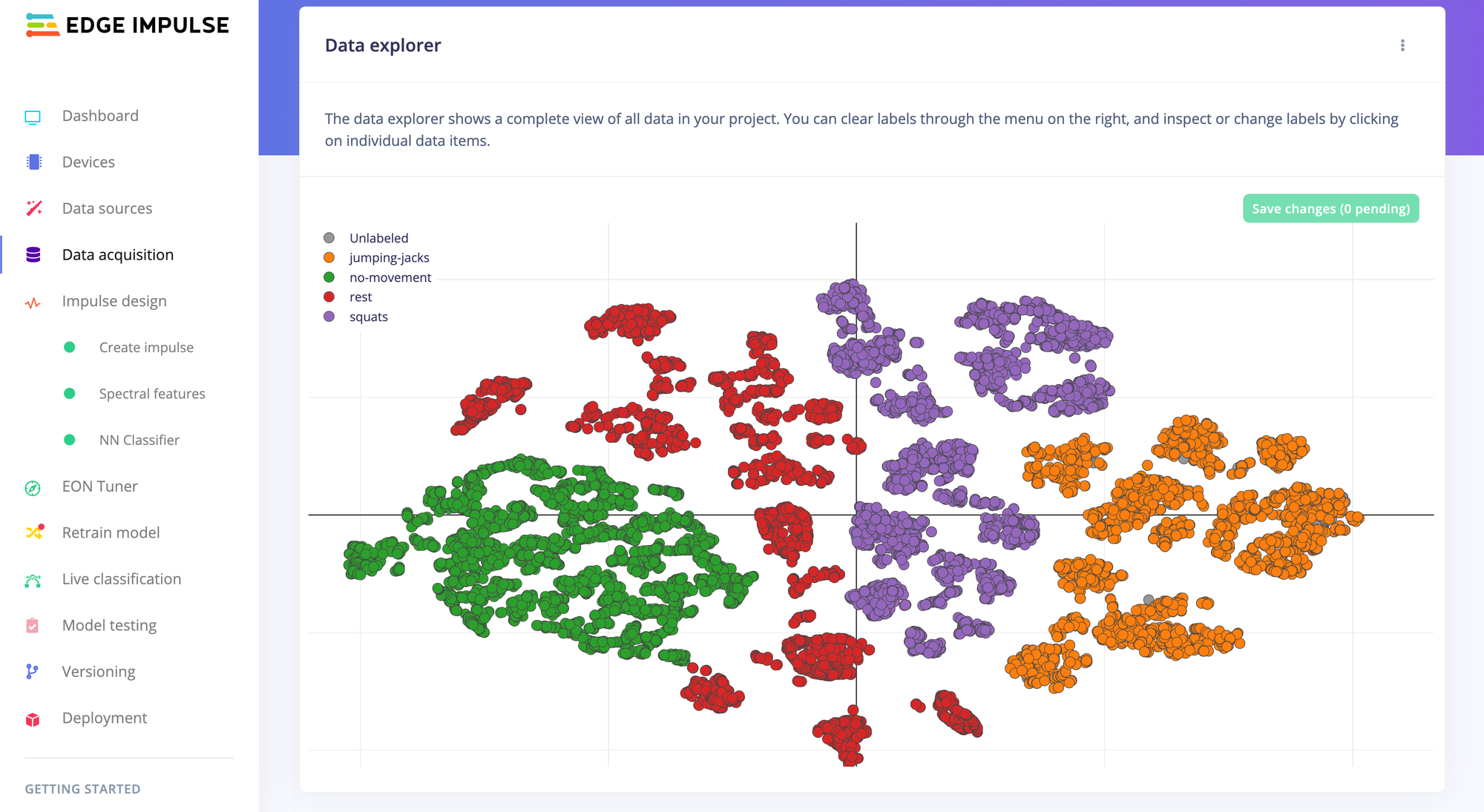
The data explorer uses a three-stage process:
- It runs your data through an input and a DSP block - like any impulse.
- It passes the result of extracted features from the DSP through part of a neural network. The final layer of the neural network is then cut off, and the derived features are returned. These features are called “embeddings.”
- The embeddings are passed through t-SNE, a dimensionality reduction algorithm.
So what makes the data explorer unique?
The data explorer allows you to see the "embeddings" of a neural network. In essence, they provide a peek into the brain of the neural network
If you see data in the data explorer that you can’t easily separate, the neural network probably can’t either - and that is a great way to spot outliers - or if there is unlabeled data close to a labeled cluster they’re probably very similar - which great for labeling unknown data.
And this introduces the assisted-labeling features directly available in the data explorer. It will point out the data samples that do not have any labels so you can properly set them. And because we have the information of their distance to the labeled clusters, all the unlabeled data samples around can inherit the same class.
Check out our data explorer documentation: https://docs.edgeimpulse.com/docs/edge-impulse-studio/data-explorer
Automate your data pipeline
The data sources feature is actually much more than just adding data from external sources. It let you create complete automated data pipelines so you can work on your active learning strategies in a few clicks.
From the data sources page, you can import datasets from existing cloud storage buckets, automate and schedule the imports, and, trigger actions such as exploring and labeling your new data using the data explorer, retraining your model, or automatically building a new deployment task.
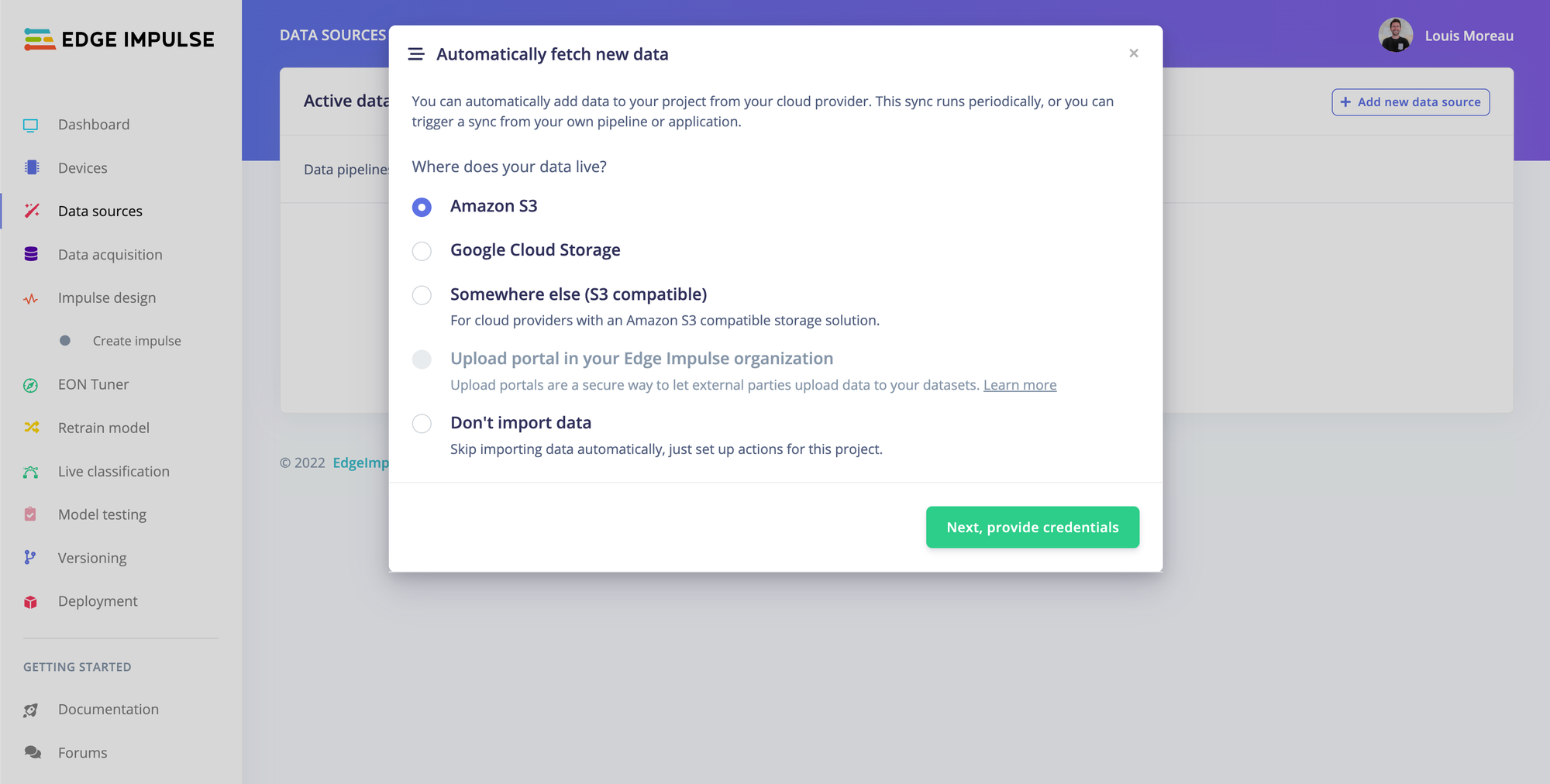
Depending on how your data are organized in your buckets, you can automatically label your samples using different strategies.
Above, we took the example of a device that recognizes the states of an industrial machine and uploads the data to specific folders based on the confidence value.
If this kind of process is set up, you can easily create automated quality datasets by directly inferring the class of the sample from the folder name or using the data explorer assisted-labeling feature to define the classes from the unknown folder.

And then you can define your pipelines, schedule jobs, and perform automated actions.
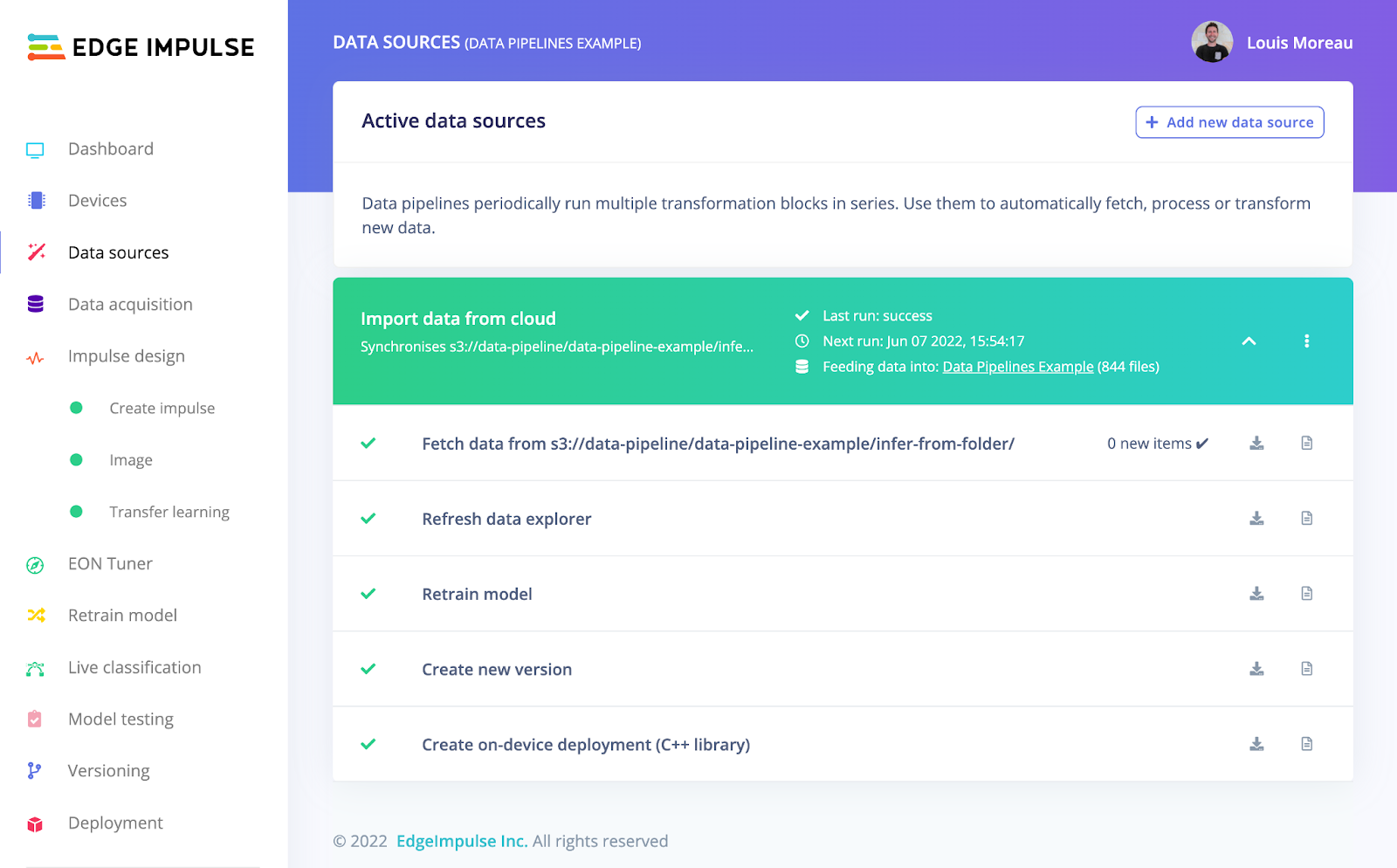
Finally, once your pipeline has finished running, you will get notified by email so you can quickly see what’s new in your project and label the missing items using the data explorer direct link.
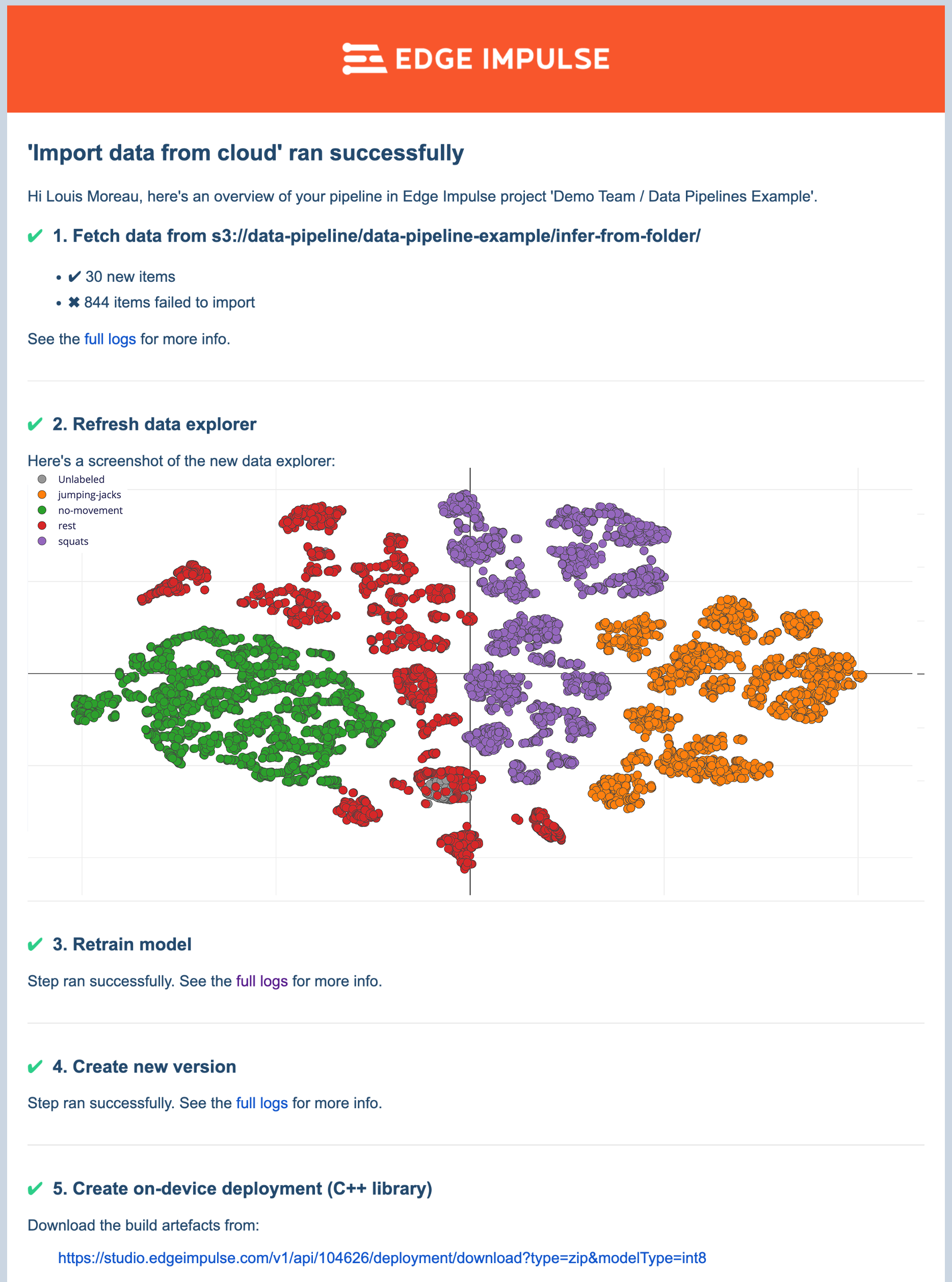
Now, if your accuracy suits you, to complete the active learning loop, you can retrieve the newly-built deployment and pass it to your device management solution to deploy it back to your device!
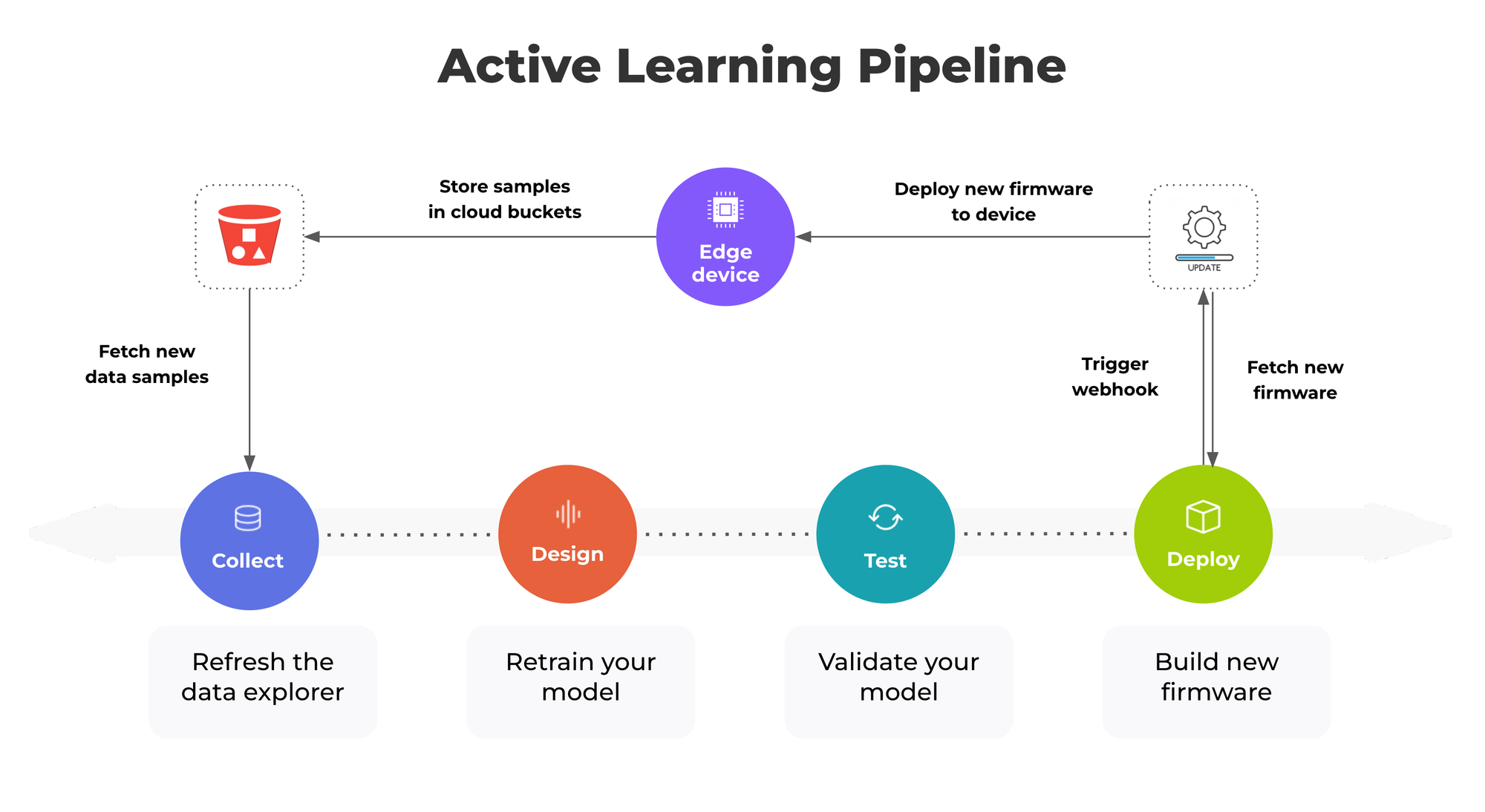
Check out our Data sources documentation: https://docs.edgeimpulse.com/docs/edge-impulse-studio/data-sources
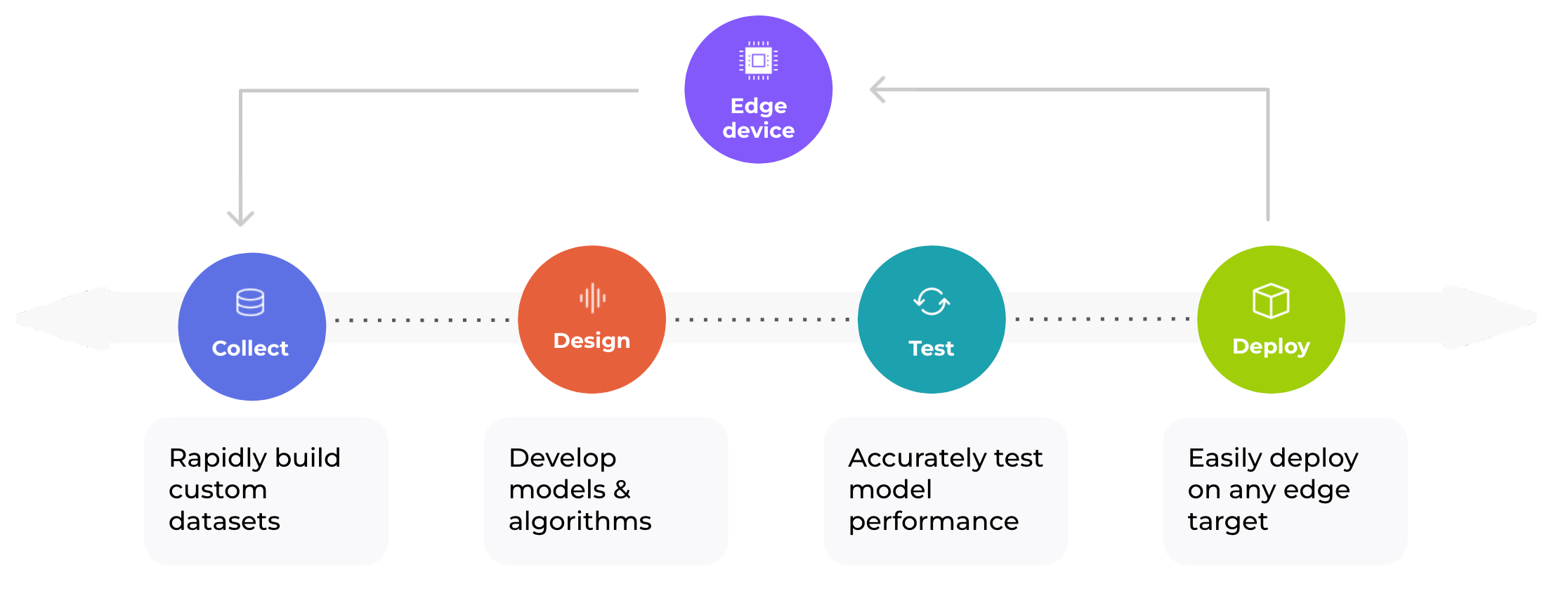
Edge Impulse let you build a fully customizable machine learning pipeline so you can accomplish a wide variety of ML tasks deployable on almost any target. We provide useful features at each step of your pipeline.
Happy discovery!