
When you are shopping for groceries at the store or picking up your mail, chances are that you do not pay much attention to the variable data labels printed on these items. Variable data labels are printed tags that each contain unique information, like a barcode, that can be used to track or identify something. Such labels can be used to track and route mail, maintain product security, or manage inventory. These are some important functions, so when something goes awry with the printing process, all sorts of problems can crop up. And with many millions of variable data labels being printed each day, issues will inevitably arise.
These issues can be caused by many factors, from varying environmental conditions to machine settings, or even the quality of the raw materials. These factors can lead to smudged lettering, ink spots, missing prints, and other defects that render the labels unreadable or inaccurate. Considering the major headaches this would lead to, it is wise to have a system in place to automatically inspect labels so that any problems can quickly be fixed before they get out of hand. A surprisingly simple, and low-cost, solution to this problem was recently demonstrated by engineer Shebin Jose Jacob. He leveraged the Edge Impulse machine learning development platform to build a prototype device that can rapidly inspect labels for common problems.

His idea was to train an object detection algorithm to recognize common label printing errors, and use it to send an alert the moment a problem is detected. A powerful Raspberry Pi 4 single-board computer was selected to provide the horsepower for the build, and a five megapixel camera gave the device the ability to capture images for analysis. Since object detection is traditionally a very computationally-intensive algorithm, Jacob chose to use Edge Impulse’s innovative FOMO algorithm that is highly accurate, yet also optimized for running on resource-constrained devices. FOMO runs 30 times faster than MobileNet SSD and only requires about 200 KB of RAM. Frame rates of up to 60 FPS have been observed when doing object detection with FOMO on the Raspberry Pi 4.
For the proof of concept, four classes of objects were chosen to focus on — ink spills, ink smudges, die cutting, and inverted labels. Jacob created 20 sample label images to represent each of these classes, then this very small dataset was uploaded to his Edge Impulse project using the data acquisition tool. The AI-assisted labeling queue was used to draw bounding boxes around each of the features that the model should recognize. Jacob noted that detecting more types of printing defects would be simple — collecting a larger dataset with representative samples of each additional defect is all that would be necessary.

An impulse was created to process the uploaded dataset. This impulse first resized the images to reduce the computational resources that would be required to run the pipeline. The preprocessed images are then forwarded into a FOMO algorithm that is tuned to recognize printed label defects. The Feature Explorer tool showed that each of the classes was well separated from the others, which means that the input data appears to contain a good signal for the model to learn from. Since everything checked out, the training process was initiated with the click of a button.
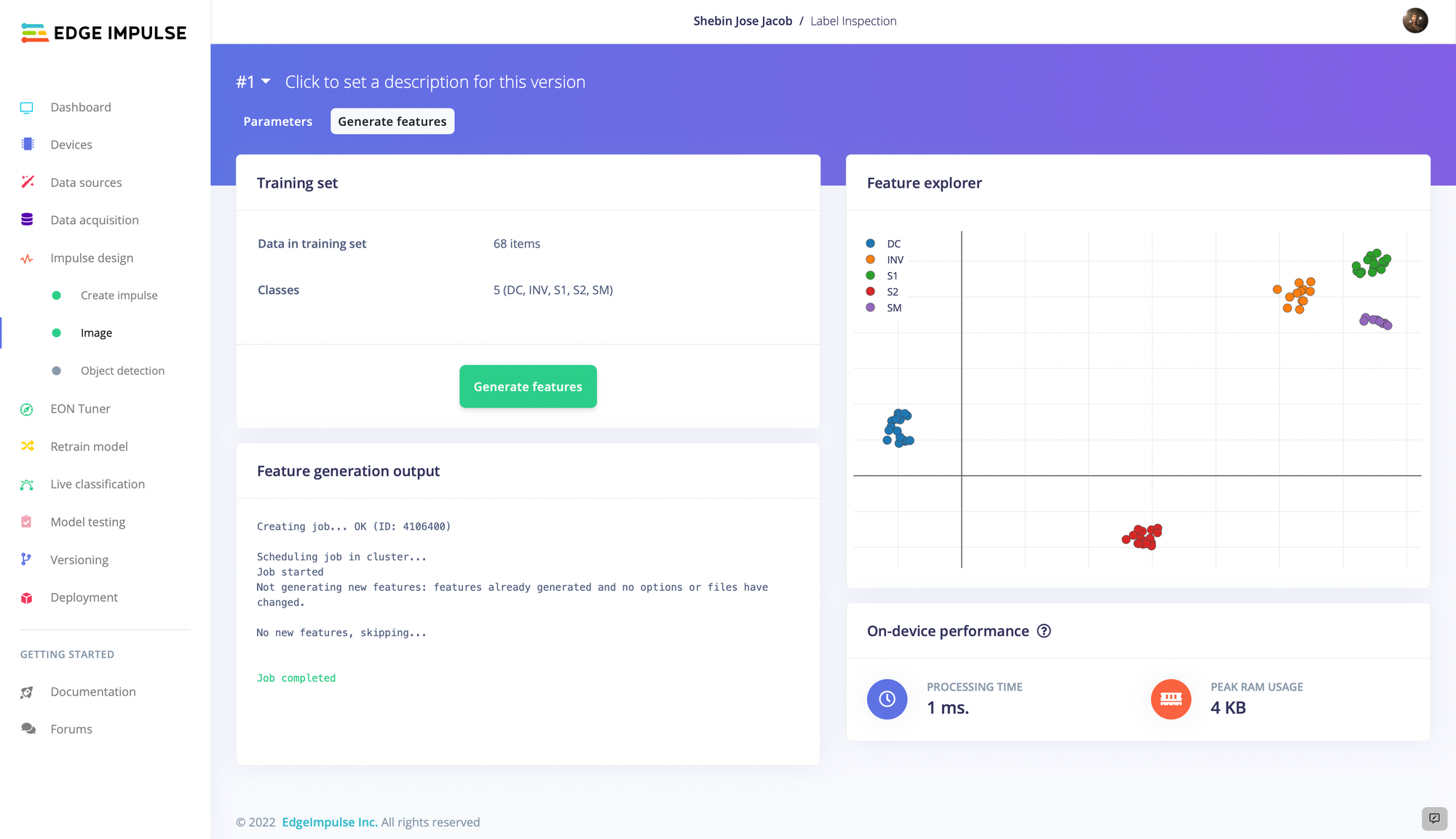
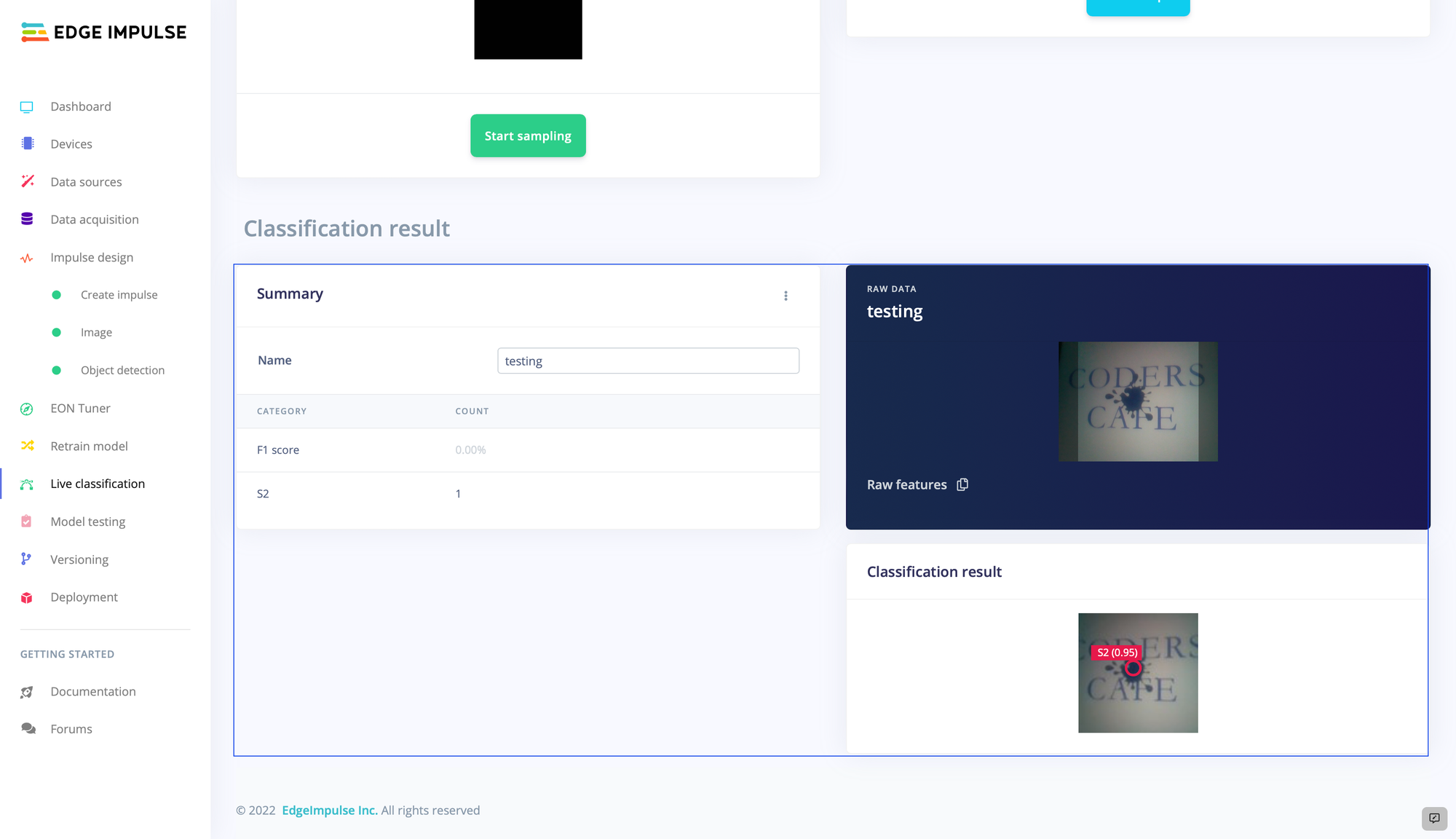
The average training accuracy was found to be a very impressive 97% after 225 training cycles. A second dataset that was not involved in the training process was used as a more stringent validation of the model. This showed that an average accuracy of 87.5% had been achieved. With only 20 samples provided per class, this is a very exceptional result. As a final validation of the algorithm, Jacob used the live classification tool to do some testing on real world data. When shown various printing defects, the model was detecting them as expected, so the only thing left to do was deploy the object detection pipeline to the Raspberry Pi.
Using the Edge Impulse for Linux CLI, the model was downloaded directly to the Raspberry Pi with just a few commands. Jacob was then able to add his own code that can act on the results of the model inferences. In this case, when a label defect is detected, a record is inserted into a Firebase real-time database. This database then drives a web application that allows the user to see any issues in real time.
If you are interested in learning how you can save time and money with your own machine learning-powered ideas, check out Jacob’s project documentation for some good tips.
Want to see Edge Impulse in action? Schedule a demo today.