
Today, we are super excited to announce the official release of a brand new approach to run object detection models on constrained devices: Faster Objects, More Objects (FOMO™).
FOMO is a ground-breaking algorithm that brings real-time object detection, tracking and counting to microcontrollers for the first time. FOMO is 30x faster than MobileNet SSD and runs in <200K of RAM.
To give you an idea, we have seen results around 30 fps on the Arduino Nicla Vision (Cortex-M7 MCU) using 245K RAM.
Image processing approaches
The two most common image processing problems are image classification and object detection.
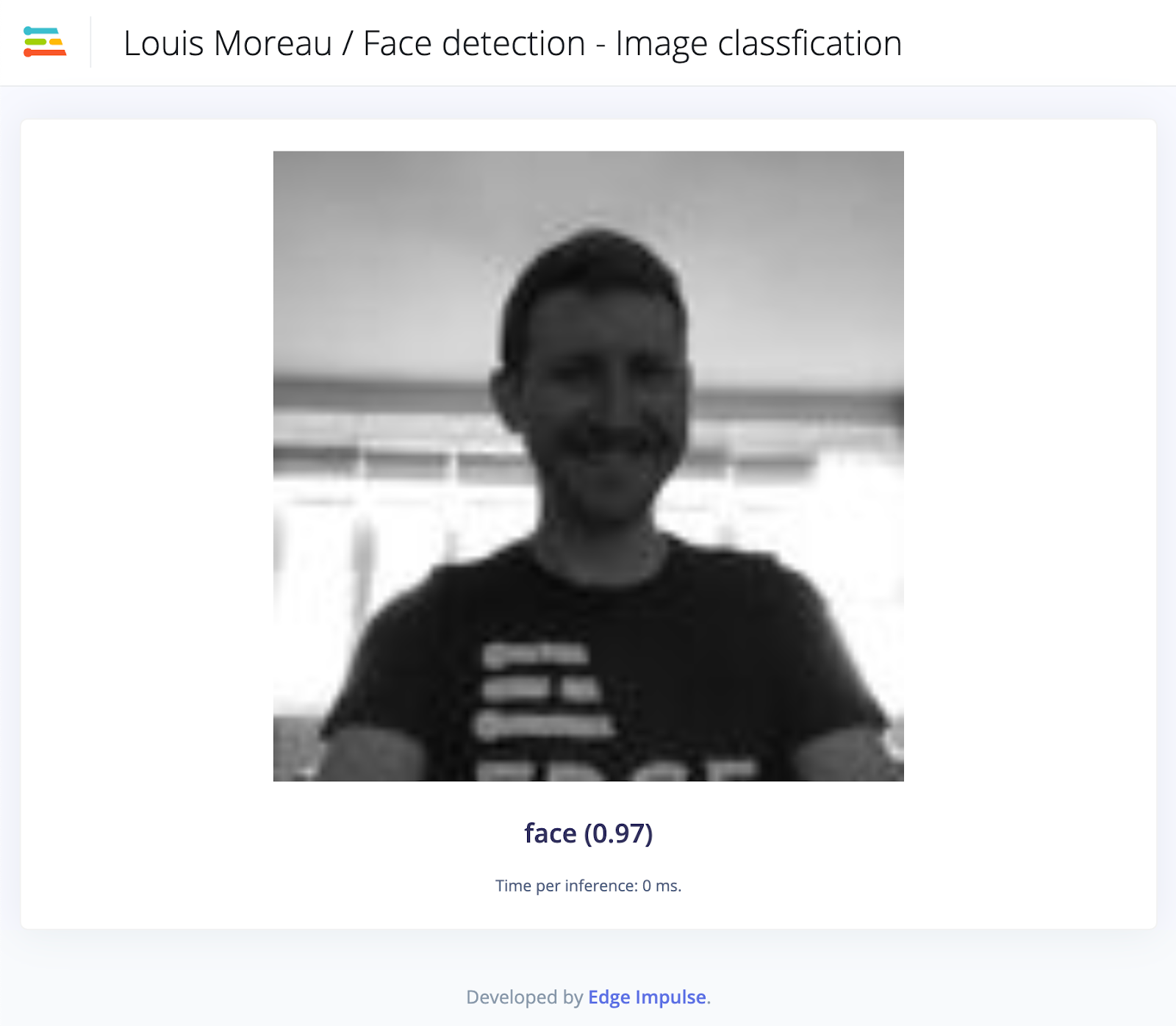
Image classification takes an image as an input and outputs what type of object is in the image. This technique works great, even on microcontrollers, as long as we only need to detect a single object in the image.
Object detection takes an image and outputs information about the class and number of objects, position, and size in the image.
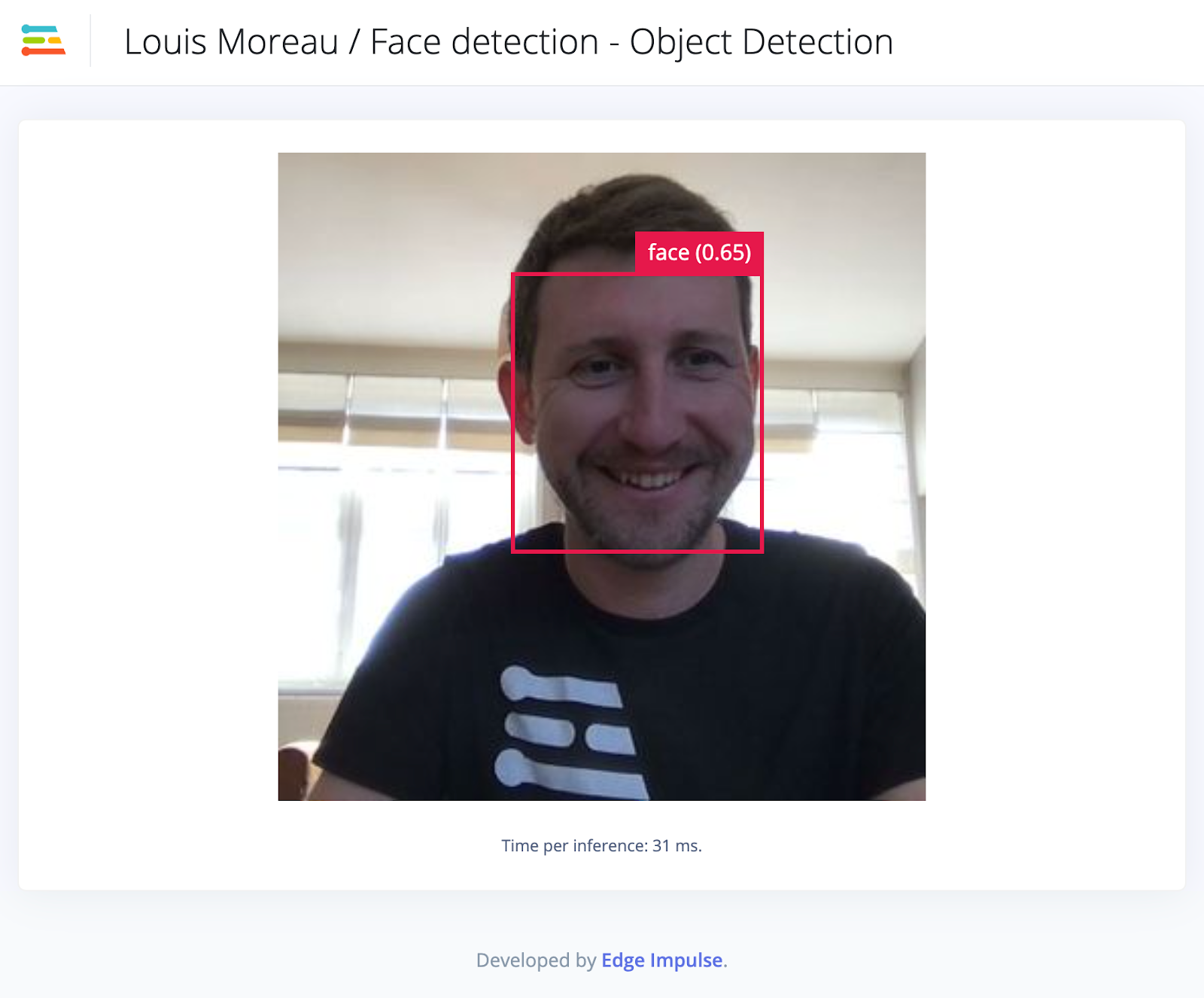
Since object detection models are making a more complex decision than object classification models they are often larger (in parameters) and require more data to train. This is why we hardly see any of these models running on microcontrollers.
The FOMO model provides a variant in between; a simplified version of object detection that is suitable for many use cases where the position of the objects in the image is needed but when a large or complex model cannot be used due to resource constraints on the device.
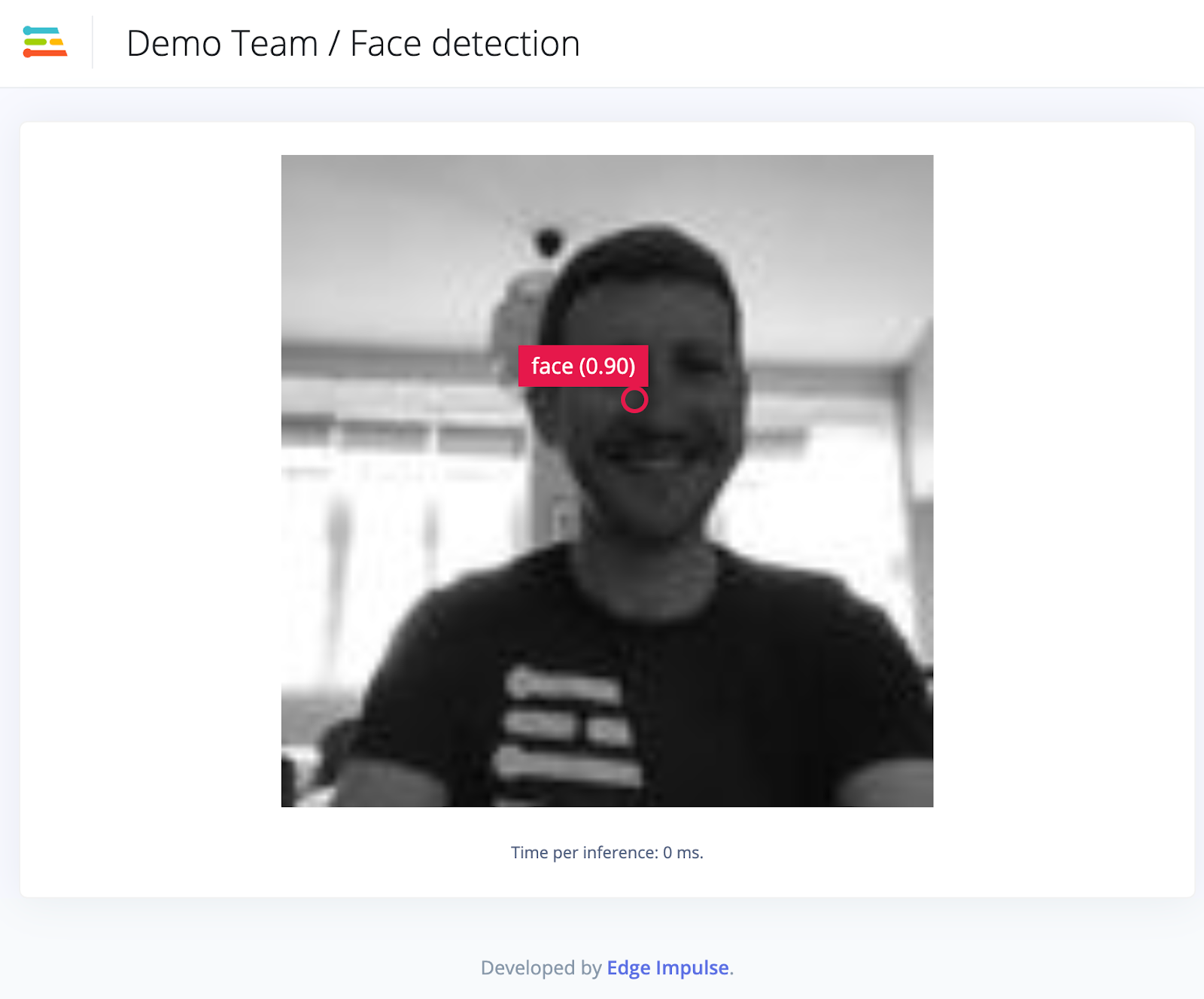
Design choices
Trained on centroid
The main design decisions for FOMO are based on the idea that a lot of object detection problems don’t actually need the size of the objects but rather just their location in the frame. Once we know the location of salient objects we can ask further questions such as "Is an object above/below another?" or "How many of these objects are in view?"
Based on this observation, classical bounding boxes are no longer needed. Instead, a detection based on the centroids of objects is enough.
Note that, to keep the interoperability with other models, your training image input still uses bounding boxes.
Designed to be flexible
Because of the underneath technique used by FOMO, when we run the model on an input image, we split this image into a grid and run the equivalent of image classification across all cells in the grid independently in parallel. By default the grid size is 8x8 pixels, which means for a 96x96 image, the output will be 12x12. For a 320x320 image, the output will be 40x40.


The resolution can be adjusted depending on the use case. You can even train on smaller patches, and then scale up during inference.
Another beauty of FOMO is its fully convolutional nature, which means that just the ratio is set and you can use it as an add-on to any convolutional image network (including transfer learning models).
Finally, FOMO can perform much better on a larger number of small objects than YOLOv5 or MobileNet SSD.
Designed to be small and amazingly fast
One of the first goals, when we started to design FOMO, was to run object detection on microcontrollers where flash and RAM are most of the time very limited. The smallest version of FOMO (96x96 grayscale input, MobileNetV2 0.05 alpha) runs in <100KB RAM and ~10 fps on a Cortex-M4F at 80MHz.
Limitations
Works better if the objects have a similar size
FOMO can be thought of as object detection where the bounding boxes are all square and, with the default configuration, 1/8th of the resolution of the input. This means it operates best when the objects are all of a similar size. For many use cases, for example, those with a fixed location of the camera, it isn’t a problem.
Objects shouldn’t be too close to each other.
If your classes are “screw,” “nail,” “bolt,” each cell (or grid) will be either “screw,” “nail,” “bolt,” and "background.” It’s thus not possible to detect distinct objects where their centroids occupy the same cell in the output. It is possible, though, to increase the resolution of the image (or to decrease the heat map factor) to reduce this limitation.
In short, if we make the following two constraining assumptions:
- All bounding boxes are square and have a fixed size
- The objects are spread over the output grid
Then we can vastly reduce the complexity, and hence the size and speed of our model. In that case, FOMO will work in its optimal condition.
Going further
FOMO documentation page: https://docs.edgeimpulse.com/docs/fomo-object-detection-for-constrained-devices
Start building a project with FOMO: https://studio.edgeimpulse.com
Happy discovery!