
When we hear about machine learning - whether it’s about machines learning to play Go, or computers generating plausible human language - we often think about deep learning. Lots of unstructured data get thrown in a complex neural network with billions of parameters, and after a very expensive training stage, the model learns the task at hand.
But this is not always a desirable approach. One of the most interesting places where we can run machine learning is on embedded or IoT devices. These devices already handle a vast amount of high-resolution sensor data, but often need to send the sensor data to the cloud to get analyzed. Because most of these devices either run off a battery or have bandwidth constraints, they discard most of their data. For example, a device with an accelerometer might sample data 100 times per second, but then only send out the peak and average motion out every hour.
This means that a lot of interesting events are missed. Smaller vibrations that might be indicative of failure are never seen, and completely different behavior might get missed because the average motion remains the same. Machine learning allows you to do a full analysis of the sensor data directly on the device, and only send the conclusion back to the cloud. That saves power, bandwidth, and allows to detect much more complex events.
But, At first sight, it seems that deep learning and embedded devices are incompatible. Deep learning models are very large, take a long time to run, and are often a black box. Embedded devices are constrained in processing power and memory (a typical embedded device might have an 80 MHz processor and only 128K of RAM), and are deployed in places where predictability and accountability are valued - if the model tells us that a machine is likely to break, it’s great if we can also reason about this.
Signal processing to the rescue
So how can we do better? Naturally, analysis of sensor data on embedded devices is nothing new, for decades developers have been using signal processing to extract interesting features from raw data. The result of the signal processing is then interpreted through simple rule-based systems. E.g. a message is sent when the total energy in a signal crosses a threshold. While these systems work it’s hard to detect complex events, as you’d need to program out every potential state.
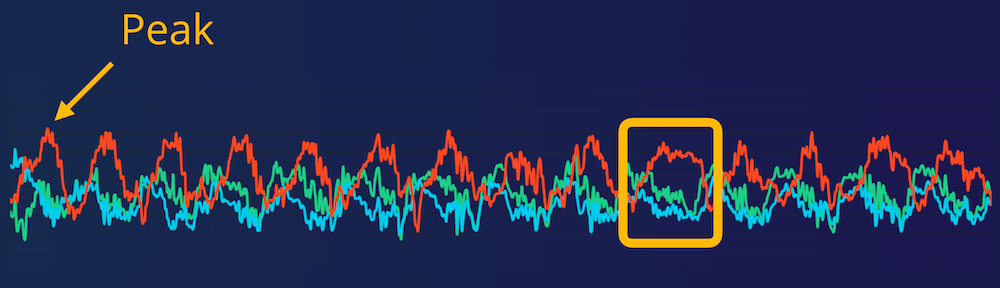
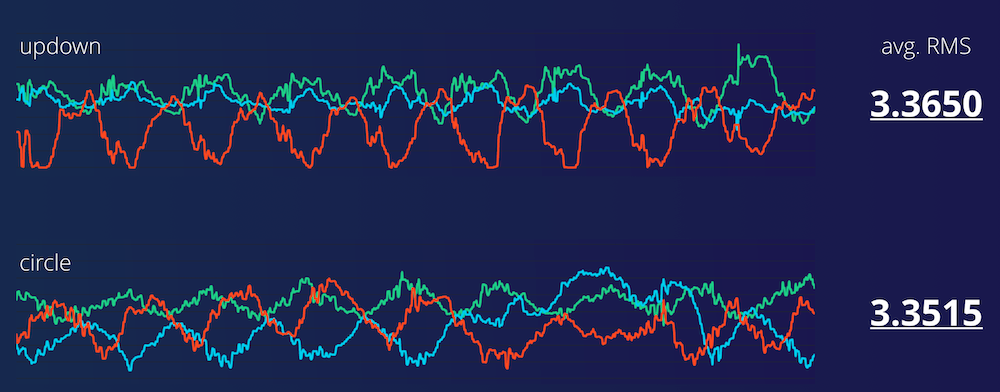
Visualizing three motions as measured on an accelerometer (fistbump, updown, and drinking a beer). On the left raw data, and on the right the same data after signal processing. The signal on the right separates much better, and you can use much smaller machine learning models to analyze this data.
But, if you retain the signal processing pipeline, and replace the rule-based system with a machine learning model, you get the best of both worlds. Because you already know the interesting features you don’t need a large deep neural network, and because the machine learning model can capture every small variation in your data, you can detect much more complex events than you can do by hand.
You can use this for example in anomaly detection. You can train a machine learning model (not even necessarily a neural network) that looks at all the data in your dataset, cluster these based on the output of a signal processing pipeline (using K-means clustering), and then compare new data to the clusters. The model learns all the potential variations in your data and creates thresholds that are much more precise and fine-grained as you could build by hand.
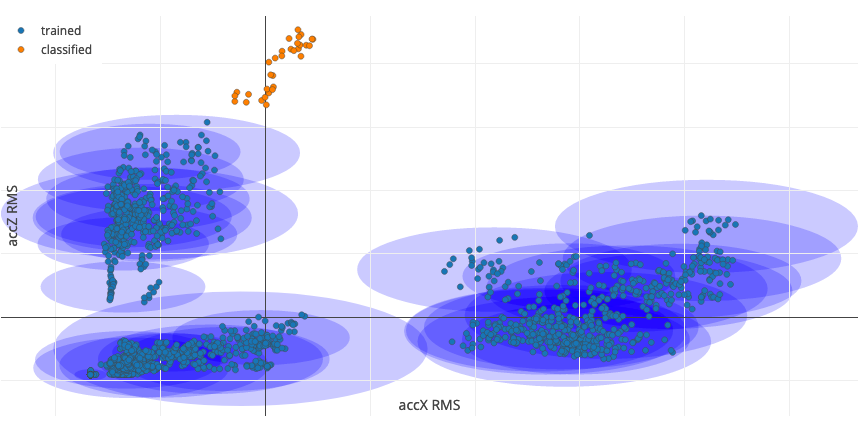
A small machine learning model that learned clusters. The blue dots represent training data, the blue circles are clusters that the machine learning model learned. The orange dots are incoming new data. As the data is outside any known cluster this is an anomaly.
Neural networks
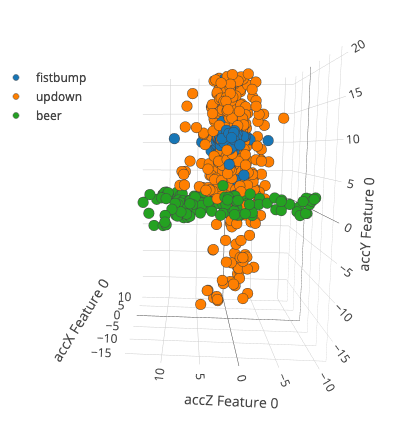
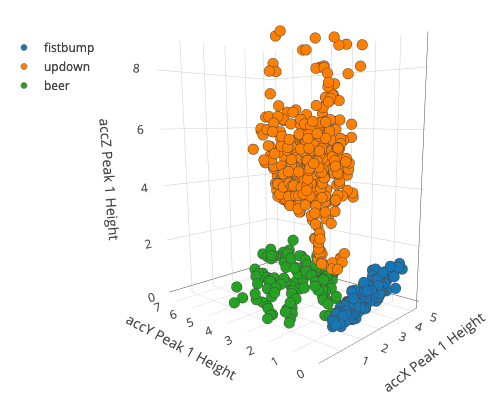
This approach is not limited to just anomaly detection. Because the signal processing step cleaned up the data and reduced the number of variables - here two seconds of high-resolution 3-axis accelerometer data is compressed down to 33 features - you can train very small neural networks to do complex event classification that works incredibly well, and are efficient enough to run on embedded systems.
For instance, a gesture recognition system that detects six different gestures using a deep neural network, which takes raw data and figures out the features itself (using an unquantized neural network with 2 convolutional layers) can analyze a second worth of data in 98 ms. on a Cortex-M4F running at 80 MHz *.
A smarter approach, using a combination of signal processing and a small neural network for classification (using a fully connected neural network with 2 hidden layers), analyzes the same data with similar accuracy in only 9 ms. (11 times faster!) on the same hardware, also using significantly less memory.
The same approach also works for other sensors. For example, raw waveform audio (16,000 samples per second) can easily be compressed to only 600 features. Paired with a small convolutional neural network this allows you to detect complex audio events in real-time on embedded devices (here’s a great write-up).
* Naturally, this will also get better over time. Companies like Arm and Google are working incredibly hard on building hardware-optimized versions of these algorithms and making networks smaller through quantization and pruning. There are also companies like Eta Compute that add support for these types of operations in hardware. It’s an exciting time for the industry!
Excited?!
At Edge Impulse we believe that very soon machine learning will be a tool in the toolbox of every embedded developer. Machine learning allows you to detect much more complex events directly on-device, reducing the amount of data that you need to send back to your application. However, that does not mean that machine learning is a magic button you can press to add intelligence to your deployment.
We still need excellent signal processing pipelines and would be foolish to throw away the accumulated knowledge we created as an industry over the past decades. Also, machine learning should also not be a black box. We should be able to reason about decisions and building smaller models that don’t rely on deep learning help with this.
If you’re excited and want to start building your first embedded machine learning model, then sign up for Edge Impulse. You can capture data from real devices, design signal processing pipelines (we ship with excellent blocks for vibration and audio analysis, but you can also bring your own), create machine learning models, and deploy your models back to any embedded device.
We can’t wait to see what you’ll build!
Jan Jongboom is the CTO and co-founder at Edge Impulse.